AI: A Technical History
I enjoyed learning about the history of machine learning and the computational methods that led to artificial intelligence. I’ve tried to take some of that and put it into a timeline to help me appreciate and understand it. Hope anyone reading this enjoys walking through it as well.
The timeline shows how AI development has clustered - long quiet periods followed by rapid advances. The last decade has seen more progress than the previous 50 years combined.
A comprehensive documentary on the history of AI from its origins to modern breakthroughs
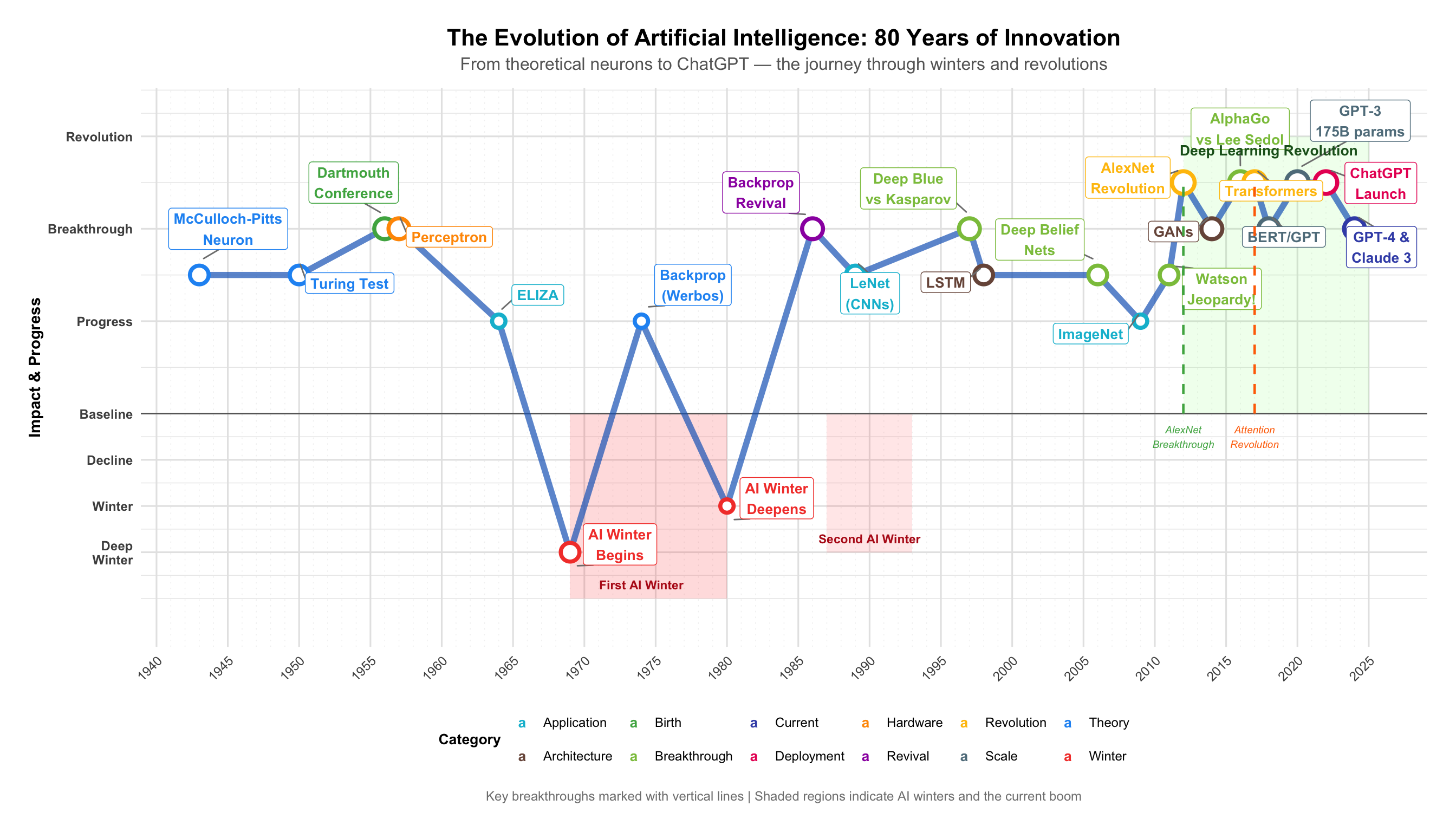
The Complete AI Timeline
Scroll horizontally to explore 80 years of breakthroughs, winters, and revolutions.
| Era | Year | Breakthrough | Key People | Impact | Significance |
|---|---|---|---|---|---|
| Foundations | 1943 | McCulloch-Pitts Neuron | McCulloch & Pitts | First mathematical neuron | ▲ Paradigm Shift |
| Foundations | 1950 | Turing Test | Alan Turing | Intelligence test defined | ◆ Major Advance |
| Foundations | 1956 | Dartmouth Conference | McCarthy & Minsky | AI field born | ▲ Paradigm Shift |
| Foundations | 1957 | Perceptron | Frank Rosenblatt | First learning hardware | ◆ Major Advance |
| Foundations | 1959 | Machine Learning Coined | Arthur Samuel | ML as improving with experience | ● Important |
| Foundations | 1965 | ELIZA | Joseph Weizenbaum | First chatbot | ○ Notable |
| Foundations | 1966 | ALPAC Report | - | MT funding cuts | ▼ Winter/Setback |
| Foundations | 1969 | Perceptrons Book | Minsky & Papert | Triggered AI winter | ▼ Winter/Setback |
| First Winter | 1973 | Lighthill Report | James Lighthill | UK cuts AI funding | ▼ Winter/Setback |
| First Winter | 1974 | Backprop (Thesis) | Paul Werbos | Invented but ignored | ● Important |
| First Winter | 1975 | MYCIN | Edward Shortliffe | Expert system success | ○ Notable |
| First Winter | 1979 | Stanford Cart | Hans Moravec | 1 meter/5 minutes | − Minor |
| Revival | 1980 | Expert Systems Boom | - | Commercial AI | ○ Notable |
| Revival | 1982 | Hopfield Networks | John Hopfield | Memory networks | ○ Notable |
| Revival | 1985 | NetTalk | Terry Sejnowski | Learns pronunciation | ○ Notable |
| Revival | 1986 | Backprop Rediscovered | Rumelhart, Hinton, Williams | Multi-layer nets trainable | ▲ Paradigm Shift |
| Revival | 1987 | Second AI Winter | - | Expert systems fail | ▼ Winter/Setback |
| Revival | 1989 | LeNet (CNN) | Yann LeCun | Digit recognition | ◆ Major Advance |
| Statistical ML | 1990 | Recurrent Networks | Jeffrey Elman | Temporal dynamics | ● Important |
| Statistical ML | 1995 | Support Vector Machines | Cortes & Vapnik | Max-margin classifiers | ◆ Major Advance |
| Statistical ML | 1997 | LSTM | Hochreiter & Schmidhuber | Solved vanishing gradient | ▲ Paradigm Shift |
| Statistical ML | 1997 | Deep Blue beats Kasparov | IBM Team | First superhuman game AI | ◆ Major Advance |
| Statistical ML | 2001 | Random Forests | Leo Breiman | Ensemble learning | ● Important |
| Statistical ML | 2006 | Deep Belief Networks | Geoffrey Hinton | Deep nets trainable | ◆ Major Advance |
| Statistical ML | 2009 | ImageNet Dataset | Fei-Fei Li | 14M images enabled DL | ▲ Paradigm Shift |
| Statistical ML | 2010 | ReLU Activation | Nair & Hinton | No vanishing gradients | ◆ Major Advance |
| Deep Learning | 2012 | AlexNet | Krizhevsky et al. | 41% error reduction | ▲ Paradigm Shift |
| Deep Learning | 2013 | Word2Vec | Tomas Mikolov | Semantic embeddings | ● Important |
| Deep Learning | 2014 | GANs | Ian Goodfellow | Adversarial generation | ◆ Major Advance |
| Deep Learning | 2014 | VGGNet | Oxford Team | 19 layers deep | ○ Notable |
| Deep Learning | 2015 | ResNet | Kaiming He | 152+ layers | ◆ Major Advance |
| Deep Learning | 2015 | Batch Normalization | Ioffe & Szegedy | Stabilized training | ● Important |
| Deep Learning | 2016 | AlphaGo beats Lee Sedol | DeepMind | Mastered Go | ▲ Paradigm Shift |
| Deep Learning | 2016 | Neural Machine Translation | End-to-end translation | ● Important | |
| Transformer Era | 2017 | Transformer | Vaswani et al. | Attention mechanism | ▲ Paradigm Shift |
| Transformer Era | 2018 | BERT | Bidirectional pretraining | ◆ Major Advance | |
| Transformer Era | 2018 | GPT-1 | OpenAI | Unsupervised pretraining | ● Important |
| Transformer Era | 2020 | GPT-3 | OpenAI | 175B parameters | ▲ Paradigm Shift |
| Transformer Era | 2021 | CLIP | OpenAI | Vision-language | ◆ Major Advance |
| Transformer Era | 2021 | AlphaFold 2 | DeepMind | 50-year problem solved | ▲ Paradigm Shift |
| Transformer Era | 2022 | Stable Diffusion | Stability AI | Open source diffusion | ◆ Major Advance |
| Transformer Era | 2022 | ChatGPT | OpenAI | 100M users in 2 months | ▲ Paradigm Shift |
| Transformer Era | 2023 | GPT-4 | OpenAI | Multimodal reasoning | ▲ Paradigm Shift |
| Transformer Era | 2023 | Llama 2 | Meta | Open 70B model | ◆ Major Advance |
| Transformer Era | 2024 | Claude 3 | Anthropic | Constitutional AI | ◆ Major Advance |
| Transformer Era | 2024 | o3 | OpenAI | 87.5% on ARC-AGI | ▲ Paradigm Shift |
Part I: Foundations (1843-1969)
Ada Lovelace and the Idea of Symbolic Computation (1843)
To understand artificial intelligence, we need to start with a fundamental question: what is computation? For most of human history, calculation meant arithmetic - adding, subtracting, manipulating numbers. The word “computer” itself referred to human beings, often women, who performed calculations by hand in astronomy observatories and ballistics labs. But in 1843, a young woman named Ada Lovelace saw something that would take humanity another century to fully appreciate: computation wasn’t about numbers at all. It was about patterns and transformations.
Lovelace was translating a French article about Charles Babbage’s Analytical Engine, a mechanical computer designed but never built. To appreciate the audacity of this machine, consider that it was conceived in the age of steam engines and gas lamps, decades before the electric light bulb. The Engine was revolutionary for its time - it had a “mill” (what we’d now call a CPU), a “store” (memory with a capacity of 1,000 50-digit numbers), and could be programmed with punched cards borrowed from the Jacquard loom. But everyone, including Babbage himself, saw it as a very sophisticated calculator. Babbage called it his “thinking machine,” but he meant it could think about numbers, nothing more.
Lovelace’s notes, which she labeled A through G, ended up being three times longer than the original article. She worked on them for nine months, corresponding extensively with Babbage, who called her “the Enchantress of Numbers.” In Note G, she laid out an algorithm for calculating Bernoulli numbers - a sequence important in number theory. This algorithm, with its loops and conditional branches, is considered the first computer program. She even included what we’d now recognize as a trace table, showing the machine’s state at each step of execution. She had invented debugging before there were bugs to debug. But that’s not why she matters to AI.
The crucial insight came in Note A, where she articulated what philosophers now call the “Lovelace objection” to machine intelligence. She wrote: “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform. It can follow analysis; but it has no power of anticipating any analytical relations or truths.” This seems like a limitation - and indeed, Alan Turing would spend considerable time addressing this very objection a century later. But then she continued with a vision that went far beyond her time: “Supposing, for instance, that the fundamental relations of pitched sounds in the science of harmony and of musical composition were susceptible of such expression and adaptations, the engine might compose elaborate and scientific pieces of music of any degree of complexity or extent.”
Pause and consider what she’s suggesting here. In 1843, when the most complex machines were pocket watches and steam engines, she imagined a device composing symphonies. Not playing music from a preset pattern like a music box, but creating new compositions based on encoded rules of harmony. She saw that creativity itself might be computational.
Think about what she’s saying. Music isn’t numbers, but it can be represented by numbers - frequencies, durations, intervals. A middle C is 261.63 Hz, an octave higher is exactly double. The pleasing sound of a major chord comes from simple frequency ratios: 4:5:6. Once represented symbolically, these relationships can be manipulated computationally. She understood that the Engine could work with any symbols whose relationships could be formally expressed - what we now call “substrate independence.” This is the birth of an idea that would take a century to realize: intelligence might be symbol manipulation. Thought might be computation.
Lovelace even anticipated machine learning, writing that the Engine might act upon “any objects whose mutual fundamental relations could be expressed by those of the abstract science of operations.” She saw that once you could represent knowledge symbolically, you could transform it, combine it, and potentially discover new knowledge. She was describing artificial intelligence before we had electricity, let alone electronic computers.
In modern genomics, we see Lovelace’s principle everywhere. DNA isn’t inherently digital - it’s a physical molecule, a sugar-phosphate backbone with nucleotide bases attached. But we represent it as sequences of A, T, G, and C. Once digitized, we can compute on it - finding patterns across billions of base pairs, predicting protein folding from sequence alone, identifying disease variants among the three billion letters of the human genome. Machine learning can even decode the “grammar” of gene regulation, understanding how cells read and interpret genetic instructions. Lovelace saw this possibility when “computer” still meant a person who calculated by hand, when the idea of encoding biological information was pure fantasy.
McCulloch-Pitts: The Brain as a Logic Machine (1943)
A century after Lovelace, the question remained: how does thinking actually work? The year was 1943, and while the world was consumed by war, two researchers at the University of Chicago were waging their own battle against the mystery of the mind. Their answer would launch the field of artificial neural networks and fundamentally change how we think about intelligence itself.
Warren McCulloch was a neurophysiologist with the soul of a philosopher. He had trained in psychology, philosophy, and medicine, earning his MD from Columbia. But his real obsession was understanding how the wet, biological matter of the brain could give rise to logic, reasoning, and consciousness. He had spent years studying the brain’s structure, mapping neural pathways with the primitive tools of the 1940s - silver staining, light microscopy, and endless patience. He knew that neurons were cells that received electrical signals from other neurons through connections called synapses. When enough signal accumulated, the neuron would “fire,” sending its own signal forward like a biological relay switch. But how did this create thought? How could meat think?
Walter Pitts was a mathematical prodigy with an unusual and tragic background. At 12, he had run away from home to escape an abusive father and spent three days hiding in a library, where he discovered Russell and Whitehead’s Principia Mathematica. Instead of comic books or adventure stories, this homeless child read all three volumes cover to cover - a work on the foundations of mathematics so dense that most PhD students find it impenetrable. He found errors in it and wrote to Russell with corrections. At 15, still homeless and living in Chicago, he would sneak into Russell’s lectures at the University of Chicago, sitting in the back row, taking notes on scraps of paper. Russell was so impressed when they finally met that he invited Pitts to study with him at Cambridge, though Pitts was too young and too poor to accept. Instead, Pitts lived in the university’s steam tunnels, emerging for lectures and seminars like a mathematical phantom.
McCulloch and Pitts met through their mutual interest in how the brain computes. The 42-year-old physician and the 20-year-old homeless genius formed an unlikely partnership. McCulloch would later say that Pitts was the greatest genius he ever knew. They would work through the night in McCulloch’s home, with McCulloch’s wife Rook feeding them and trying to convince Pitts to sleep in a bed instead of on the floor. Their collaboration produced a 1943 paper with an unwieldy title: “A Logical Calculus of Ideas Immanent in Nervous Activity.” But the idea was elegant, even beautiful in its simplicity.
They proposed that neurons could be modeled as simple logical units, stripping away all the messy biology to reveal the computational essence. Their model was audaciously reductionist: forget about neurotransmitters, ion channels, and the hundred types of neurons in the brain. Instead, imagine each neuron as a simple decision-maker that follows three rules. First, it receives inputs from other neurons, like votes in an election. Second, each input has a weight - positive for excitatory inputs (“yes” votes), negative for inhibitory inputs (“veto” votes). Third, the neuron sums all these weighted votes, and if the total exceeds a threshold, the neuron fires its own signal forward.
In mathematical terms, this became beautifully simple: Output = 1 if Σ(weight × input) > threshold, else 0. It’s a democracy of neurons, where each cell votes on whether the next should fire.
This seems almost trivially simple - so simple that some dismissed it as a toy model. But McCulloch and Pitts proved something profound using the mathematical tools of their time: networks of these simple units could compute any logical function that could be computed at all. You could build AND gates (fire only if all inputs fire), OR gates (fire if any input fires), NOT gates (fire if input doesn’t fire). They showed explicit constructions: two neurons with carefully chosen weights could implement any Boolean function. String enough together, and you could build any circuit. And if you could build any circuit, you could build a computer. The brain might be a biological implementation of a universal computing machine.
The implications were significant. If thought was computation, and computation could be mechanized, then perhaps machines could think. They had reduced the ineffable quality of mind to binary decisions and weighted connections.
But there was a deeper implication that connected their work to the foundations of computer science itself. In 1936, Alan Turing had proven that his abstract “Turing machines” could compute any function that could be computed - a result so fundamental it defined what we mean by “computable.” Now McCulloch and Pitts showed that neural networks had the same property. They were “Turing complete.” This created an extraordinary equivalence: Turing machines, neural networks, and (presumably) biological brains were all computationally equivalent. They could all compute the same set of functions.
This meant three important things. First, the brain might be a computer in Turing’s formal sense - not metaphorically, but literally, a physical implementation of a universal computing machine. Second, we might be able to build artificial brains from non-biological components, since what mattered was the computation, not the substrate. Third, and most radically, thinking itself might be computation - not like computation, but actually computation, in the same way that heat is molecular motion, not merely like molecular motion.
But there was a crucial limitation in their model: the weights and thresholds were fixed, hardwired like a circuit board. The network couldn’t learn. It was like having a brain that was fully formed at birth, unable to adapt or improve from experience. This was particularly ironic, since the human brain’s defining characteristic is its plasticity - children learn languages effortlessly, we form new memories daily, and stroke patients can rewire their brains to recover lost functions. McCulloch and Pitts had captured the brain’s logic but not its ability to change.
In clinical practice, this adaptability is crucial. A diagnostic algorithm with fixed rules might correctly identify textbook cases of pneumonia or heart failure, but medicine is full of exceptions. The same symptoms that suggest heart failure in a 70-year-old might indicate something entirely different in a pregnant woman or a marathon runner. The ability to learn from new cases, to update beliefs based on evidence, to recognize that each patient is unique - this is what separates useful AI from brittle rules. McCulloch and Pitts had given us the neuron. Someone else would have to teach it to learn.
Their paper would inspire a generation of researchers, but Pitts himself would have a tragic end. After a falling out with McCulloch over personal matters, he burned all his unpublished work and became a recluse, dying at 46 with most of his ideas lost forever. McCulloch would continue advocating for their vision until his death in 1969, just as the first AI winter was beginning.
The Cybernetics Movement: Feedback and Control (1948-1950)
Lex Fridman’s introduction to deep learning fundamentals
While McCulloch and Pitts were modeling neurons, a broader movement was emerging around the idea of intelligent machines. They called it “cybernetics” - from the Greek word for “steersman” - and it would provide crucial concepts for AI.
Norbert Wiener and Feedback (1948)
Norbert Wiener was an MIT mathematician who had worked on anti-aircraft systems during World War II. The problem was predicting where a plane would be by the time your shell arrived. This required the gun to track the plane, predict its path, and adjust - a feedback loop.
In his 1948 book “Cybernetics: Or Control and Communication in the Animal and the Machine,” Wiener proposed that feedback loops were fundamental to both biological and artificial systems. Your body maintains temperature through feedback: too hot, you sweat; too cold, you shiver. Your hand picks up a glass through feedback: visual and tactile signals continuously adjust your grip.
For AI, this meant learning could be viewed as a feedback process. Try something, observe the error, adjust, repeat. This cybernetic view would influence everything from robotics to reinforcement learning. In medical AI, we use this principle constantly - a diagnostic model makes a prediction, we observe the outcome, and the model updates its parameters. The learning is in the loop.
Claude Shannon and Information Theory (1948)
At Bell Labs, Claude Shannon was trying to solve a practical problem: how to send messages reliably over noisy phone lines. His solution created an entire field: information theory.
Shannon’s key insight was that information could be quantified. He defined information as reduction in uncertainty, measured in “bits” (binary digits). A coin flip has 1 bit of information. A dice roll has about 2.6 bits. This gave us a mathematical way to talk about knowledge, learning, and communication.
For neural networks, Shannon’s work provided the mathematical framework for understanding how information flows through layers, how much information each connection carries, and how learning changes information content. When we talk about “cross-entropy loss” in modern deep learning, we’re using Shannon’s mathematics.
Grey Walter’s Tortoises: Emergent Behavior (1949-1950)
W. Grey Walter, a neurophysiologist at the Burden Neurological Institute in Bristol, built some of the first autonomous robots. He called them “tortoises” (Machina speculatrix), and gave them whimsical names: Elmer and Elsie.
Each tortoise had just two vacuum tubes acting as neurons, yet they exhibited surprisingly complex behavior. They explored their environment, moving toward light sources when their batteries were charged. When power ran low, they would navigate back to their charging station. Upon encountering obstacles or other tortoises, they would navigate around them. Most remarkably, when placed in front of a mirror, they would engage in what appeared to be a “dance” with their reflection.
These simple machines demonstrated that complex behavior could emerge from simple rules without explicit programming for each action. This principle - that intelligence might emerge from the interaction of simple units rather than from complex programming - would become fundamental to AI research.
The Turing Test: Defining Intelligence by Behavior (1950)
Alan Turing had spent World War II at Bletchley Park, leading the effort to break the Enigma code. His work shortened the war by an estimated two years and saved millions of lives. After the war, he turned his attention to a question that had haunted him since his youth: can machines think?
The problem with “Can machines think?” is that we don’t have a good definition of “thinking.” Is it consciousness? Self-awareness? The ability to feel? Philosophers had debated these questions for millennia without resolution.
In his 1950 paper “Computing Machinery and Intelligence,” Turing did something clever. He replaced the question “Can machines think?” with “Can machines do what we (as thinking entities) do?”
He proposed the Imitation Game, now known as the Turing Test: 1. A human interrogator sits in a room, connected by teletype to two other rooms 2. One room contains a human, the other a computer 3. The interrogator asks questions and receives typed responses 4. If the interrogator cannot reliably determine which respondent is the machine, the machine passes
This approach was elegant in its simplicity. It avoided metaphysical debates about consciousness by focusing on observable behavior rather than internal states. It provided a concrete, achievable goal for AI research and implicitly defined intelligence as the ability to use language intelligently.
Turing predicted that by the year 2000, machines would be able to fool interrogators 30% of the time in a five-minute conversation. Modern systems like GPT-4 can maintain convincing conversations, but the deeper question - whether they truly understand or merely pattern-match - remains open.
In medical AI, we face a similar challenge. When a diagnostic AI correctly identifies a rare disease from a pathology slide, is it “seeing” cancer the way a pathologist does, or is it matching patterns? Turing’s insight was that for practical purposes, it might not matter.
The Dartmouth Workshop: Naming the Field (1956)
In the summer of 1956, a 29-year-old assistant professor at Dartmouth named John McCarthy wanted to organize a workshop on “thinking machines.” But he needed a better name for his grant proposal to the Rockefeller Foundation. After some deliberation, he coined the term “Artificial Intelligence.”
The proposal was audacious. McCarthy and his co-organizers - Marvin Minsky (Harvard), Nathaniel Rochester (IBM), and Claude Shannon (Bell Labs) - claimed: “We propose that a 2-month, 10-man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College… The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.”
They planned to tackle: The proposal outlined seven key research areas: automatic computers (programming languages), programming computers to use language, neuron nets (neural networks), computational complexity theory, self-improvement (machine learning), abstractions and concepts, and randomness and creativity.
The attendee list included pioneers who would shape the field for decades. Allen Newell and Herbert Simon from Carnegie Tech presented their Logic Theorist program, arguably the first AI program capable of proving mathematical theorems. Arthur Samuel from IBM demonstrated a checkers program that could improve through self-play. Ray Solomonoff and Oliver Selfridge contributed work on pattern recognition and learning, while Trenchard More from Princeton explored machine models of cognition.
The workshop didn’t achieve its ambitious goals. In fact, the attendees couldn’t even agree on basic approaches - some favored neural networks, others symbolic logic, still others statistical methods. But it did something crucial: it established AI as a field of study, gave it a name, and created a community of researchers.
Looking back, their timeline was hilariously optimistic. They thought major breakthroughs would come in months or years. It would take decades. But their core belief - that intelligence could be understood well enough to be replicated - would ultimately prove correct.
The Perceptron: The First Learning Machine (1957)
Frank Rosenblatt was a psychologist at the Cornell Aeronautical Laboratory who believed the key to AI wasn’t programming but learning. He had a radical idea: instead of telling a machine what to do, why not let it figure things out for itself? The McCulloch-Pitts neuron could compute, but its weights were fixed like a photograph - a frozen moment of intelligence. Real neurons, Rosenblatt knew, strengthen or weaken their connections based on experience. When you learn to ride a bike, your neural pathways literally reshape themselves. He wanted to build a machine that could do the same.
Rosenblatt was something of a renaissance man - he played classical music, wrote poetry, and sailed competitively. Perhaps this breadth gave him the audacity to believe that the mystery of learning could be reduced to a simple algorithm. His colleagues thought he was chasing moonbeams. The director of his lab reportedly told him he was wasting his time on “science fiction.” But Rosenblatt pressed on, funded by the Office of Naval Research, which was interested in pattern recognition for submarine detection and aerial reconnaissance.
His solution, which he called the Perceptron (from “perception” + “neuron”), combined three key insights that seem obvious now but were radical then:
Adjustable weights: Unlike McCulloch-Pitts neurons, the connections could be modified. He used motor-driven potentiometers - essentially volume knobs that could turn themselves - to represent synaptic strengths. Each motor’s position encoded how strongly one neuron influenced another.
A learning rule: A mathematical way to update weights based on errors. This was inspired by Donald Hebb’s 1949 theory that “neurons that fire together, wire together.”∃ If the machine made a mistake, it would strengthen connections that should have fired and weaken those that shouldn’t have.
Physical implementation: Actual hardware, not just theory. While others philosophized about machine intelligence, Rosenblatt built one. This wasn’t a computer program - it was a room-sized machine with flashing lights, whirring motors, and a camera for an eye.
The Mark I Perceptron was unveiled in 1957. It was an impressive piece of engineering:
The Hardware: The machine consisted of 400 photocells arranged in a 20×20 grid serving as a primitive retina. These were connected through randomly wired connections - Rosenblatt believed randomness was crucial for learning - to 512 motor-driven potentiometers that could rotate to adjust connection strengths. The output was a single unit that would light up for “yes” or remain dark for “no.”
How It Learned:
The learning algorithm was beautifully simple. When shown a training example:
- Forward pass: The image activated photocells, signals flowed through weighted connections, and the output unit either fired or didn’t
- Compare: Check if the output matched the correct answer
- Update: If wrong, adjust the weights:
- If it should have fired but didn’t, increase weights from active inputs
- If it fired but shouldn’t have, decrease weights from active inputs
- Repeat: Show more examples until it got them right
Mathematically, the learning rule was:
w_new = w_old + learning_rate × (target - output) × inputIf the output was correct, (target - output) = 0, so no change. If wrong, weights moved in the direction that would reduce error.
What It Could Do:
The first public demonstration was impressive. After just 50 training examples, the Perceptron could distinguish triangles from squares - a task that seems trivial now but was groundbreaking then. No one had programmed it with the definition of a triangle. It had discovered the concept itself through trial and error.
Within weeks, the perceptron demonstrated impressive capabilities. It could recognize all 26 letters of the alphabet, even in different handwriting styles. It could identify whether a shape appeared on the left or right side of its visual field. It could distinguish between different types of objects in aerial photographs - a capability of particular interest to the Navy for reconnaissance applications.
The potentiometers would physically rotate as it learned, their positions encoding the knowledge it had acquired. Journalists who visited the lab described an almost biological quality to its learning - the motors whirring and clicking like synapses forming, the machine gradually “understanding” what it was seeing. One reporter wrote that watching it learn was “like watching a child discover the world.”
The Promise and the Hype:
Rosenblatt wasn’t shy about promoting his invention - and this would ultimately contribute to AI’s first major backlash. At a press conference on July 8, 1958, at the Cornell Aeronautical Laboratory, he made claims that would haunt the field for decades. Standing next to his clicking, whirring machine, he declared that the Perceptron was “the first machine capable of having an original idea.” When pressed by skeptical reporters, he doubled down: “I don’t mean to sound like a prophet, but I believe that within 5 to 10 years, we will have machines that can read, write, and respond to human emotion.”
The Navy, which had invested $400,000 (about $4 million in today’s dollars), was even more enthusiastic. Their press release claimed the Perceptron would eventually “walk, talk, see, write, reproduce itself and be conscious of its existence.” The New York Times ran the story on its front page with the headline “NEW NAVY DEVICE LEARNS BY DOING; Psychologist Shows Embryo of Computer Designed to Read and Grow Wiser.” The article suggested that Perceptrons might one day explore distant planets, sending back reports without human supervision.
These wild promises would come back to haunt not just Rosenblatt, but the entire field of AI. When the limitations became clear, the backlash would be severe.
This wasn’t entirely hype. The Perceptron had achieved something genuinely significant: it was the first machine that could learn from examples rather than being explicitly programmed. In medical terms, it was like the difference between memorizing a textbook and learning from cases. The machine was building its own internal representation of what made a triangle different from a square.
Rosenblatt proved an important theorem: the Perceptron Convergence Theorem. If the data was linearly separable (meaning you could draw a straight line to separate the classes), the Perceptron was guaranteed to find that line. Given enough training examples, it would always converge to a solution.
But that “if” would prove to be its downfall.
Grant Sanderson’s (3Blue1Brown) brilliant introduction to neural networks - essential viewing for understanding the fundamentals
The XOR Problem and the First AI Winter (1969-1980)
By the mid-1960s, Perceptrons were everywhere. The Stanford Research Institute had one. IBM was building them. The military was funding dozens of projects. Rosenblatt himself was working on multi-layer versions he called “cross-coupled Perceptrons” and even speculating about three-dimensional arrays of Perceptrons that could model the entire visual cortex. Researchers were building Perceptrons for character recognition, speech processing, even weather prediction. Fortune magazine declared that electronic brains would create a $2 billion industry by 1970. The field seemed poised for breakthrough.
Then Marvin Minsky and Seymour Papert decided to write a book that would kill it all.
The rivalry between Minsky and Rosenblatt was both intellectual and personal. They had been high school classmates at the Bronx High School of Science, both brilliant, both ambitious. But where Rosenblatt was an optimist who saw learning machines as the path to AI, Minsky believed in symbolic reasoning and explicit programming. Where Rosenblatt built hardware, Minsky wrote software. Where Rosenblatt drew inspiration from biology, Minsky looked to logic and mathematics. Their approaches were fundamentally incompatible, and in the small world of early AI research, there wasn’t room for both visions.
Minsky had been at the Dartmouth workshop. He’d initially been enthusiastic about neural networks but had grown skeptical. Too many limitations were becoming apparent. Together with Papert, he set out to rigorously analyze what Perceptrons could and couldn’t do. Their 1969 book “Perceptrons” was meant to be constructive criticism. It became a funeral oration.
The XOR Problem:
To understand what killed the Perceptron, we need to understand XOR (exclusive OR). It’s a simple logical function: The XOR function outputs 1 when inputs differ and 0 when they’re the same: (0,0)→0, (0,1)→1, (1,0)→1, (1,1)→0.
In medical terms, think of it like this: imagine you’re trying to diagnose a condition that appears when exactly one of two symptoms is present, but not when both are present or both are absent. It’s not uncommon in medicine - drug interactions often work this way.
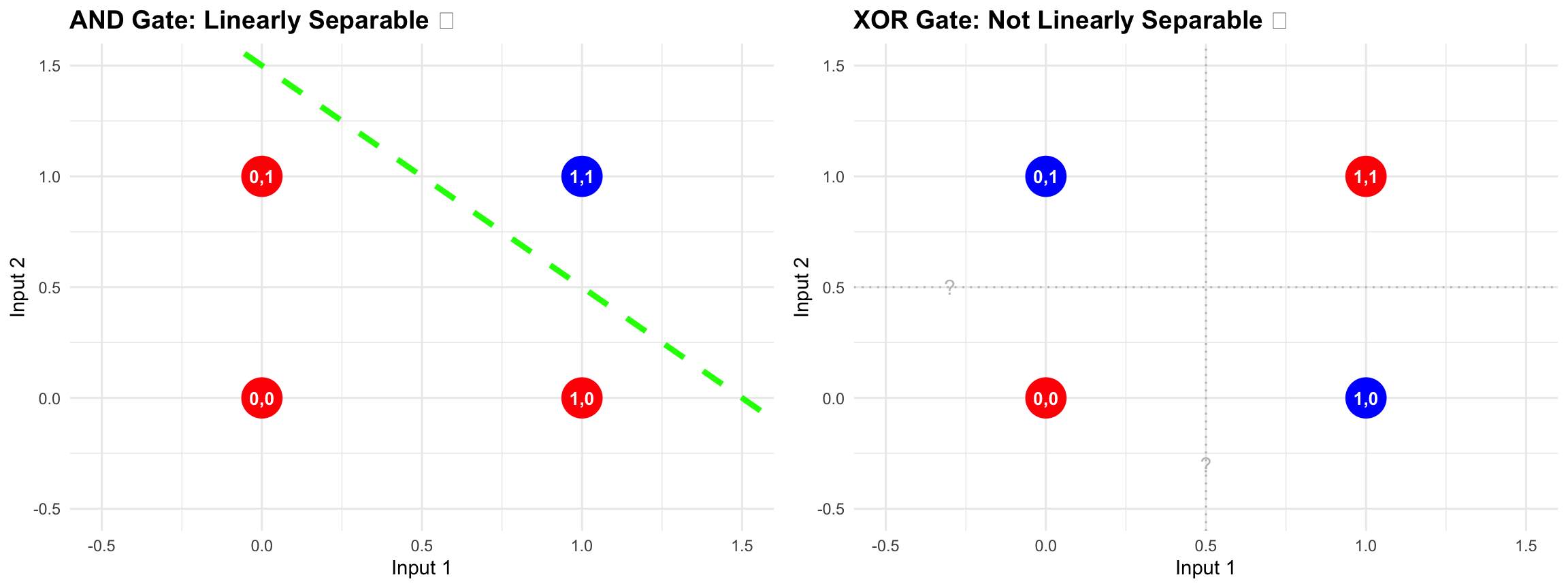
The XOR problem visualized: (Left) AND gate is linearly separable - a single line can divide the red and blue points. (Right) XOR gate requires at least two lines to separate the classes, which a single-layer Perceptron cannot learn.
Why XOR Matters:
The Perceptron makes decisions by drawing a line (or hyperplane in higher dimensions). Everything on one side of the line is class A, everything on the other side is class B. This works beautifully for problems like AND: The function places three points ((0,0), (0,1), (1,0)) with output 0 on one side of any potential line, while (1,1) with output 1 sits on the other side.
But look at XOR. The points that should output 1 are (0,1) and (1,0) - diagonally opposite corners. The points that should output 0 are (0,0) and (1,1) - the other diagonal. No single straight line can separate these diagonals. You need at least two lines, creating regions. But a Perceptron can only create two regions, not four.
Minsky and Papert didn’t just show XOR was hard - they proved it was impossible for a single-layer Perceptron. Their proof was elegant and devastating.
Here’s the tragedy: Minsky and Papert knew multi-layer networks could solve XOR. They said so in their book. But there was a catch - nobody knew how to train them. If you had hidden layers between input and output, how did you know which hidden neurons to blame when the network made a mistake? They called it the credit assignment problem, and it seemed mathematically impossible.
The money vanished overnight. DARPA pulled funding. Researchers fled to symbolic AI like rats from a sinking ship. Neural networks became career suicide.
But a few believers remained. Geoffrey Hinton, a British psychologist turned computer scientist, was convinced the brain’s massive parallelism was the key. David Rumelhart and James McClelland formed a research group in San Diego. For 17 years they worked in the wilderness, ignored by their peers, stubbornly certain that connection strengths between simple units could somehow encode intelligence.
Part II: The First AI Winter (1970-1985)
The collapse was swift and total. In 1969, neural networks were the future. By 1970, they were the past. It was as if someone had turned off the lights at a party - one moment there was music and laughter, the next, empty silence.
The immediate impact of Minsky and Papert’s book was devastating for neural network research. Graduate students abandoned their theses. Funding agencies redirected their grants. Conferences that had been standing-room-only became ghost towns. But to understand the AI Winter - a term coined by analogy to nuclear winter, suggesting a deep freeze that kills everything - we need to understand that it wasn’t just about neural networks failing. It was about the entire field of AI confronting the chasm between its promises and reality. We had promised thinking machines by 1970. What we had were toys that could barely recognize handwritten digits.
The Funding Crisis
The timing couldn’t have been worse. The late 1960s saw the U.S. deeply mired in Vietnam, hemorrhaging $25 billion a year (about $200 billion in today’s dollars) into a war that was going nowhere. Congress was scrutinizing every research dollar with the intensity of an audit. Senator Mike Mansfield, furious about wasteful defense spending, had just passed his famous amendment requiring all DARPA-funded research to have direct, demonstrable military relevance. “No more blue-sky research,” he declared on the Senate floor. “If it doesn’t help win wars, we’re not funding it.”
Perceptrons that might someday read handwritten digits didn’t qualify. Neither did robots that could stack blocks, or programs that could prove theorems. DARPA’s budget for AI research dropped from $3 million in 1969 to almost nothing by 1974. The money didn’t just decrease - it vanished, like water in the desert.
In Britain, the situation was equally grim, if more politely executed. Sir James Lighthill, a renowned mathematician who had worked on supersonic flight and fluid dynamics, was commissioned by the Science Research Council to evaluate AI research. His 1973 report was not just critical - it was a calculated assassination.
Lighthill divided AI into three categories with surgical precision: Lighthill divided AI into three categories with surgical precision. Category A encompassed automation and engineering - useful applications but essentially clever programming rather than true AI. Category B represented the core promise of AI: building genuinely intelligent, thinking machines. Category C covered studies of the central nervous system - legitimate neuroscience research but distinct from artificial intelligence.
His conclusion was stark: Category B had failed to achieve its goals and faced fundamental limitations. He introduced the concept of the “combinatorial explosion” - the exponential growth of possibilities in real-world problems. A chess program might evaluate 10 moves ahead in a toy problem, but real chess required evaluating 10^120 possible games. A blocks world program could stack five blocks, but a real robot in a real warehouse would face infinite variations of lighting, positioning, and physics. The gap between toy demonstrations and useful applications wasn’t just large - it was mathematically unbridgeable.
The BBC, smelling blood, organized a debate between Lighthill and AI researchers. It was a public execution. Lighthill, urbane and confident, demolished his opponents with calm precision. The AI researchers, used to friendly academic conferences, were unprepared for this kind of hostile scrutiny. Within months, his report ended virtually all government AI funding in Britain. Entire research groups were disbanded. Edinburgh University, which had one of the world’s leading AI labs, saw its funding cut to zero.
The result was a brain drain. Researchers fled to industry or rebranded their work. “Artificial Intelligence” became “Knowledge Engineering” or “Expert Systems” or “Decision Support Systems.” The phrase itself was toxic.
The Rise of Symbolic AI: Intelligence as Rules
With neural networks discredited and buried, AI researchers embraced a different paradigm entirely. Intelligence, they now declared, wasn’t about learning - it was about reasoning. The human mind wasn’t a network of neurons but a symbol processor, like a computer running software. We didn’t need to simulate biology; we needed to encode logic.
This approach, later dubbed “Good Old-Fashioned AI” (GOFAI) with a mixture of nostalgia and derision, had strong philosophical roots reaching back millennia. It aligned with the rationalist tradition from Aristotle through Leibniz - the dream that all reasoning could be reduced to calculation. Leibniz had imagined a universal language where philosophical arguments could be settled by computation: “Let us calculate!” he said. Now, three centuries later, AI researchers believed they could finally build his dream.
GOFAI also had practical advantages that made it irresistible to computer scientists: you could understand exactly what the system was doing and why. Every decision could be traced, every rule examined. When it failed, you knew why. When it succeeded, you could explain how. This transparency was comforting after the black-box mystery of neural networks.
Expert Systems: The Brief Golden Age
The breakthrough came with expert systems - programs that encoded human expertise as if-then rules. The idea was seductive in its simplicity: if human expertise was just accumulated knowledge, then we could bottle it like wine. Interview the experts, extract their knowledge as rules, implement those rules in code. It was industrial-age thinking applied to intelligence: mass production of expertise.
The promise was intoxicating. Imagine: the world’s best doctor available in every rural clinic. The greatest chemist working in every lab. The top financial advisor accessible to every investor. Democracy of expertise through technology. Companies saw dollar signs. Governments saw strategic advantage. The gold rush was on.
MYCIN (1976) was the poster child. Developed at Stanford by Edward Shortliffe, it diagnosed blood infections and recommended antibiotics. Its knowledge base contained about 600 rules like:
IF: The gram stain of the organism is positive
AND: The morphology of the organism is coccus
AND: The growth pattern is chains
THEN: There is suggestive evidence (0.7) that the organism is streptococcusEach rule had a certainty factor, allowing MYCIN to reason with uncertainty. In trials, MYCIN’s recommendations matched infectious disease experts 69% of the time - better than the 80% agreement rate between human experts themselves. It seemed like a triumph.
DENDRAL (1969) was even earlier, developed by Edward Feigenbaum (the “father of expert systems”). It determined molecular structures from mass spectrometry data. Unlike MYCIN’s diagnostic reasoning, DENDRAL used a generate-and-test approach: propose candidate structures, predict their spectra, compare with observed data. It was so successful that chemists actually used it for novel structure determination.
By the early 1980s, expert systems were a billion-dollar industry. Companies like DEC saved millions using XCON to configure computer systems. American Express used an expert system for credit approval. Japan launched its Fifth Generation Computer Systems project, betting their technological future on logic programming and expert systems.
The Knowledge Acquisition Bottleneck
But cracks were showing. Building expert systems required “knowledge engineers” to interview domain experts and encode their expertise. This process was excruciating:
Knowledge acquisition proved far more difficult than anticipated. Experts often couldn’t articulate their decision-making process, defaulting to “I just know” when pressed for specific rules. Different experts provided conflicting rules for the same scenarios. Rules interacted in unexpected ways, creating logical contradictions. Edge cases multiplied exponentially as systems grew. Maintenance became increasingly difficult - adding one rule could break ten existing ones.
In medicine, we encountered this constantly. A cardiologist might say, “If the patient has chest pain and shortness of breath, consider myocardial infarction.” But what kind of chest pain? How severe? What about atypical presentations in women or diabetics? The expert “just knew” from experience, but couldn’t fully articulate the nuanced pattern recognition they performed.
The Brittleness Problem
Expert systems were brilliant within their narrow domains but catastrophically brittle outside them. MYCIN could diagnose bacteremia but was useless for viral infections. Show it a fungal infection, and it would confidently recommend antibiotics that wouldn’t work. It had no concept of “I don’t know.”
This brittleness wasn’t a bug - it was fundamental. The systems had no real understanding, just rules. They couldn’t reason by analogy, couldn’t learn from experience, couldn’t handle novel situations. They were like medical students who had memorized a textbook but had never seen a patient.
The Common Sense Problem: The most ambitious attempt to save symbolic AI came from Marvin Minsky himself. If the problem was that AI lacked common sense, then the solution was obvious: give it common sense. How hard could it be?
Very hard, it turned out. Minsky’s “frames” tried to capture stereotypical situations - what happens when you enter a restaurant (host seats you, waiter brings menu, you order, food arrives, you eat, you pay). Roger Schank created “scripts” for event sequences - going to a birthday party involves cake, candles, singing, presents, games. Douglas Lenat launched Cyc (from “encyclopedia”), aiming to encode all human common sense knowledge. By 1985, they had encoded thousands of facts: water is wet, things fall down, dead people stay dead, you can’t be in two places at once, rain makes things wet, fire is hot, glasses break when dropped.
But common sense was an ocean, and they were trying to capture it with a thimble. A four-year-old knows that if you turn a cup of water upside down, the water falls out - unless the cup has a lid, or it’s frozen, or you’re in space, or it’s actually a magic trick cup. Every rule had exceptions, every exception had exceptions. The knowledge engineers went mad trying to encode the obvious. One famously quit after spending six months trying to formally define “edge” (as in the edge of a table). The project continues to this day, now with over 10 million assertions. It still can’t match a toddler’s understanding of the world.
The Lighthill Report was the kill shot. In 1973, mathematician James Lighthill told the British government that AI had failed. It worked on “toy problems” but collapsed on real-world complexity. Britain cut AI funding to zero. America followed. The winter had begun.
The Underground
While the mainstream chased rules and logic, the neural network believers went underground. They couldn’t get funding, couldn’t publish in top journals, couldn’t use the words “neural network” without ridicule.
But they had each other. David Rumelhart and James McClelland started the Parallel Distributed Processing group in San Diego. Geoffrey Hinton, exiled to Carnegie Mellon, kept pushing. They met in small workshops, circulated manuscripts by hand, and slowly, carefully, worked on the credit assignment problem.
They knew something the symbol manipulators didn’t: intelligence wasn’t about rules. It was about connection patterns. The brain didn’t run logical inferences; it settled into states. Memory wasn’t retrieval; it was reconstruction. Learning wasn’t programming; it was weight adjustment.
By 1985, the expert systems bubble was bursting. They cost too much, broke too easily, and couldn’t learn. The stage was set for one of the great comebacks in scientific history.
Part III: The Connectionist Revival (1986-1998)
The solution to the credit assignment problem was hiding in every calculus textbook, waiting patiently like a key under a doormat that everyone had walked past for fifteen years.
In 1986, the San Diego PDP (Parallel Distributed Processing) group published their two-volume manifesto. It was 1,200 pages of vindication for everyone who had kept faith during the winter. But the real bombshell was buried in chapter 8 of volume 1 - a 40-page paper by David Rumelhart, Geoffrey Hinton, and Ronald Williams that would resurrect neural networks from the dead. They called their method “backpropagation.”
The idea was almost insultingly simple. So simple that when Rumelhart first explained it at a conference, several researchers reportedly slapped their foreheads in a mixture of enlightenment and embarrassment. When the network makes an error at the output, you use the chain rule from first-year calculus to figure out how much each weight contributed to that error. Then you adjust each weight proportionally. Work backward from output to input, layer by layer, propagating the error signal like a wave traveling upstream. Hence, backpropagation.
The tragedy - or perhaps the comedy - was that it wasn’t even new. Paul Werbos had described the exact same algorithm in his 1974 PhD thesis, titled “Beyond Regression.” But Werbos was an economist at Harvard studying social systems, not a computer scientist. His thesis was filed away in the economics library where no AI researcher would ever look. Seppo Linnainmaa had invented automatic differentiation in Finland in 1970, published in his master’s thesis in Finnish. Even earlier, Arthur Bryson and Yu-Chi Ho had described it for control theory in 1969. The solution had been rediscovered at least four times, unknown to each discoverer. The neural network community had spent fifteen years in exile for want of an algorithm that multiple people had already invented.
The Backpropagation Breakthrough
Backpropagation worked not because it was complex, but because it was simple enough to actually implement. The beauty was in its recursive elegance: the error at any layer could be computed from the error at the next layer. It was like a cascade of responsibility, each layer passing blame backward until every weight knew exactly how much it had screwed up.
Understanding gradient descent - the optimization algorithm behind all neural network learning
The intuition behind backpropagation - how neural networks actually learn
The math was clean:
∂E/∂w_ij = ∂E/∂o_j × ∂o_j/∂net_j × ∂net_j/∂w_ijThat’s just the chain rule. Every calculus student learns it. But when applied to neural networks, it solved the unsolvable. Multi-layer networks could finally learn.
They demonstrated it on XOR - the problem that had killed the field. The network learned it easily. They tried harder problems. The network learned those too. After 17 years in the wilderness, neural networks were back.
The Art of Teaching Networks
Backpropagation told you which direction to adjust weights. But how much? Too little and training took forever. Too much and you’d overshoot, oscillating wildly. This was the art of optimization - navigating mountainous loss landscapes in thousands of dimensions.
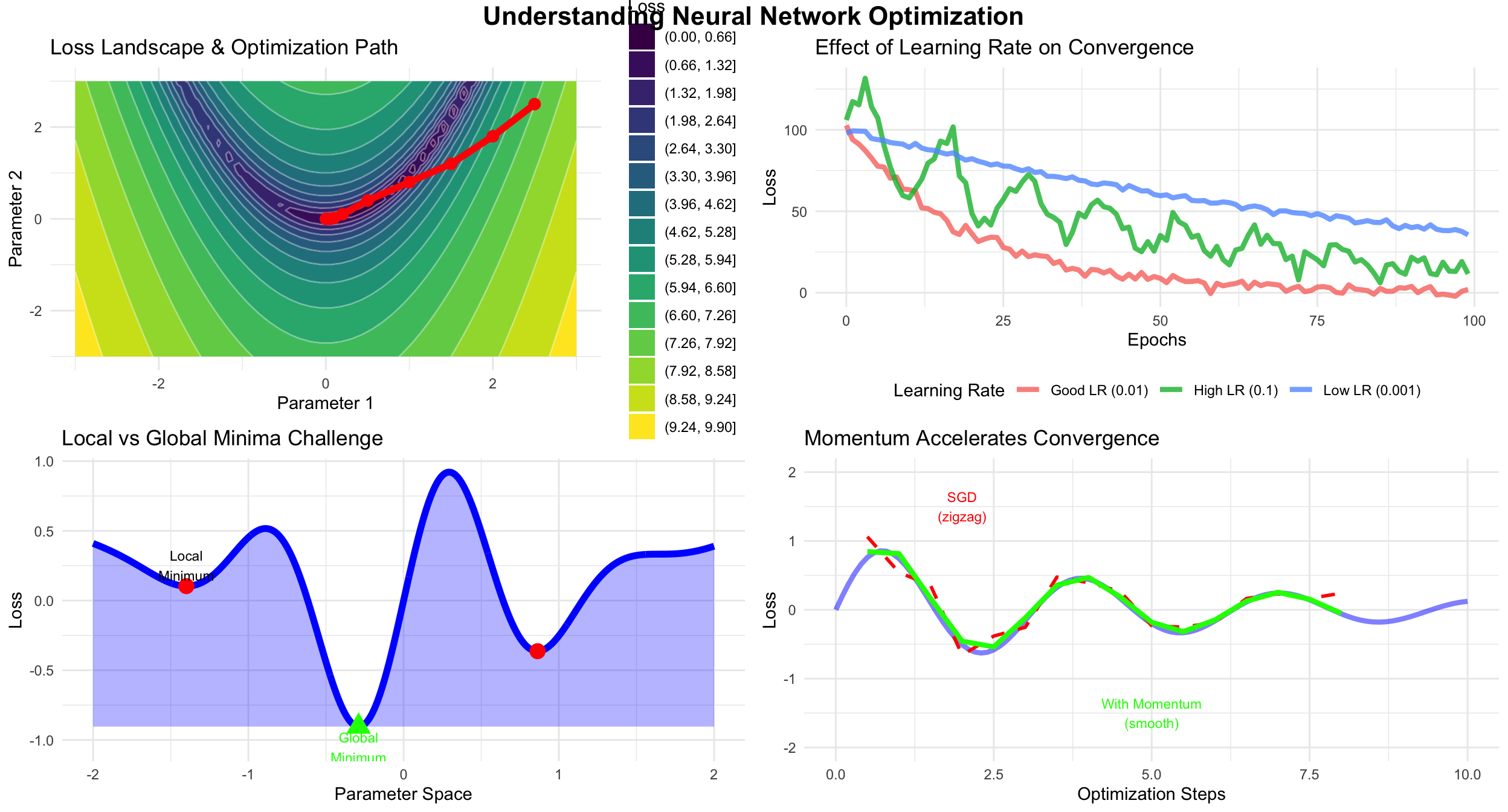
Key optimization insights: Loss landscapes in neural networks are complex, high-dimensional surfaces containing many local minima. The learning rate proves crucial for navigation - too high causes oscillation and instability, too low results in prohibitively slow convergence. Local minima were long feared as training obstacles, but modern networks are sufficiently wide that most local minima achieve acceptable performance. Momentum techniques help escape shallow minima while accelerating convergence in consistent gradient directions.
Convolutional Neural Networks: Building in a Priori Knowledge (1989)
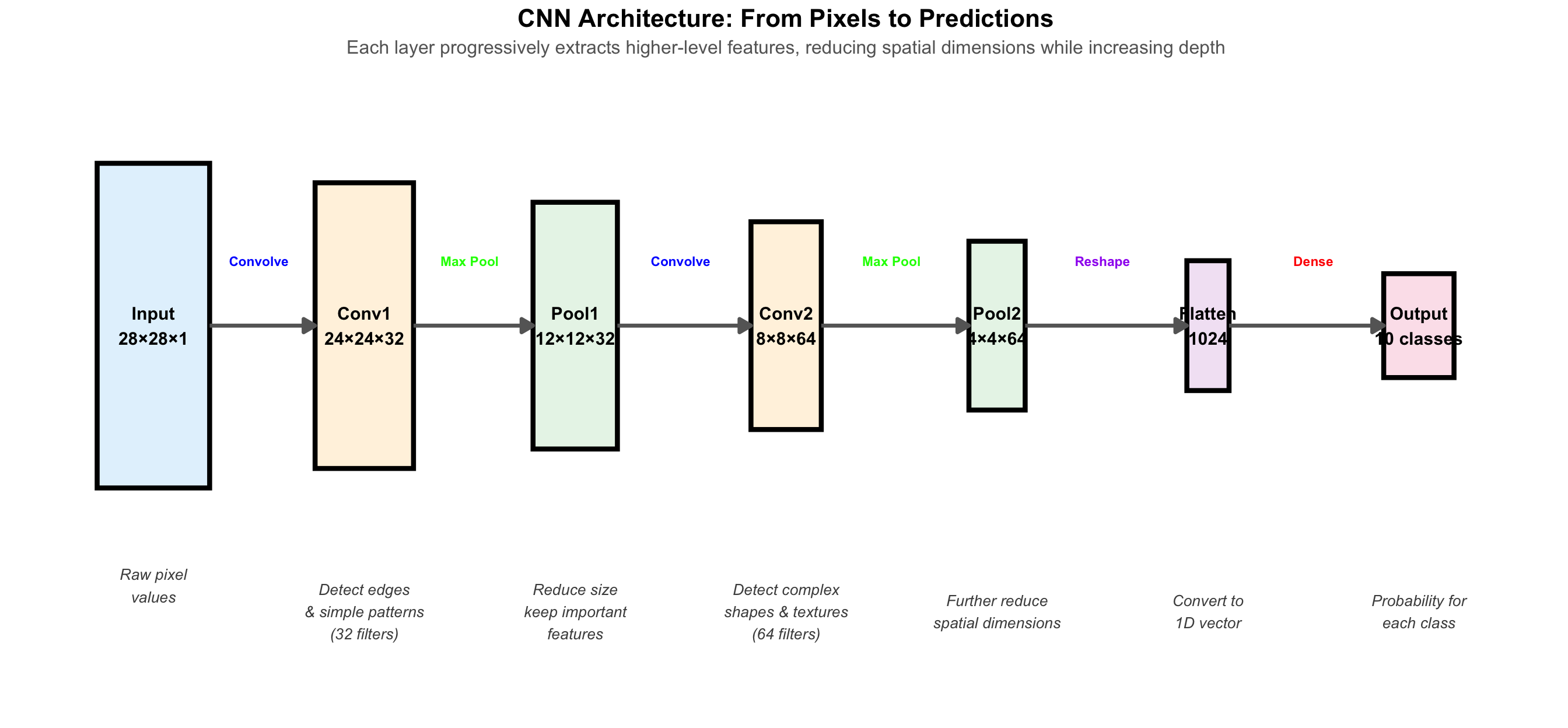
CNN layers work together: Convolution detects patterns (edges→shapes→objects), Pooling reduces size while preserving important features, Fully Connected combines all features for final classification.
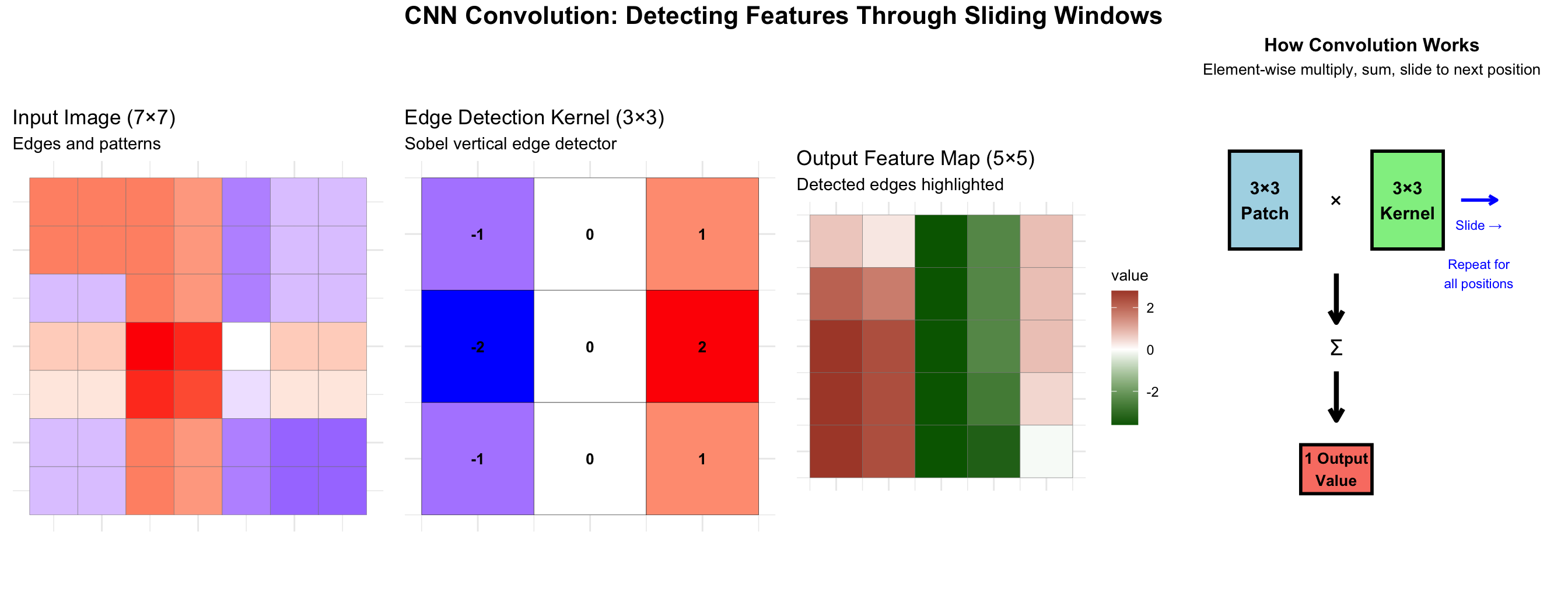
The convolution operation: A small kernel slides across the image, computing dot products to detect specific patterns like edges.
Yann LeCun’s Beautiful Insight (1989)
While everyone else was building fully connected networks - where every neuron talked to every other neuron - Yann LeCun was studying cat brains.
Hubel and Wiesel had won the Nobel Prize for discovering that visual neurons were arranged in a hierarchy. Early neurons detected edges. Later neurons combined edges into shapes. Even later neurons recognized objects. And crucially, each neuron only looked at a small patch of the visual field.
LeCun realized this wasn’t an accident - it was an engineering solution. Images have local structure. Pixels near each other are related. Patterns repeat across the image. Why make the network learn what evolution had already discovered?
His Convolutional Neural Networks built these insights directly into the architecture:
• Local connections: Each neuron only looked at a small window, like 5×5 pixels. This cut parameters by 99%.
• Weight sharing: The same feature detector slid across the entire image. If it could spot a vertical edge in one place, it could spot it anywhere.
• Pooling: After detecting features, shrink the image. Keep the important stuff, throw away precise positions.
It was biomimicry at its finest. By 1998, LeCun’s LeNet-5 was reading millions of handwritten checks for banks, saving them hundreds of millions of dollars. Neural networks weren’t just back - they were making money.
The Memory Problem (1990-1997)
Images were spatial. Language was temporal. You couldn’t understand “bank” without knowing if the previous words were “river” or “financial.” Networks needed memory.
Jeffrey Elman’s answer was elegant: connect the network to itself. Take the hidden layer’s activation and feed it back as input on the next time step. Now the network had memory - it could remember what it had seen.
Except it couldn’t. Not really. The memory faded exponentially. After 5-7 words, the network had forgotten everything. They called it the vanishing gradient problem. As you backpropagated through time, the gradient got multiplied by weights at each step. Small weights? The gradient vanished to zero. Large weights? It exploded to infinity.
Understanding RNNs and LSTMs - the architecture that enabled sequence modeling
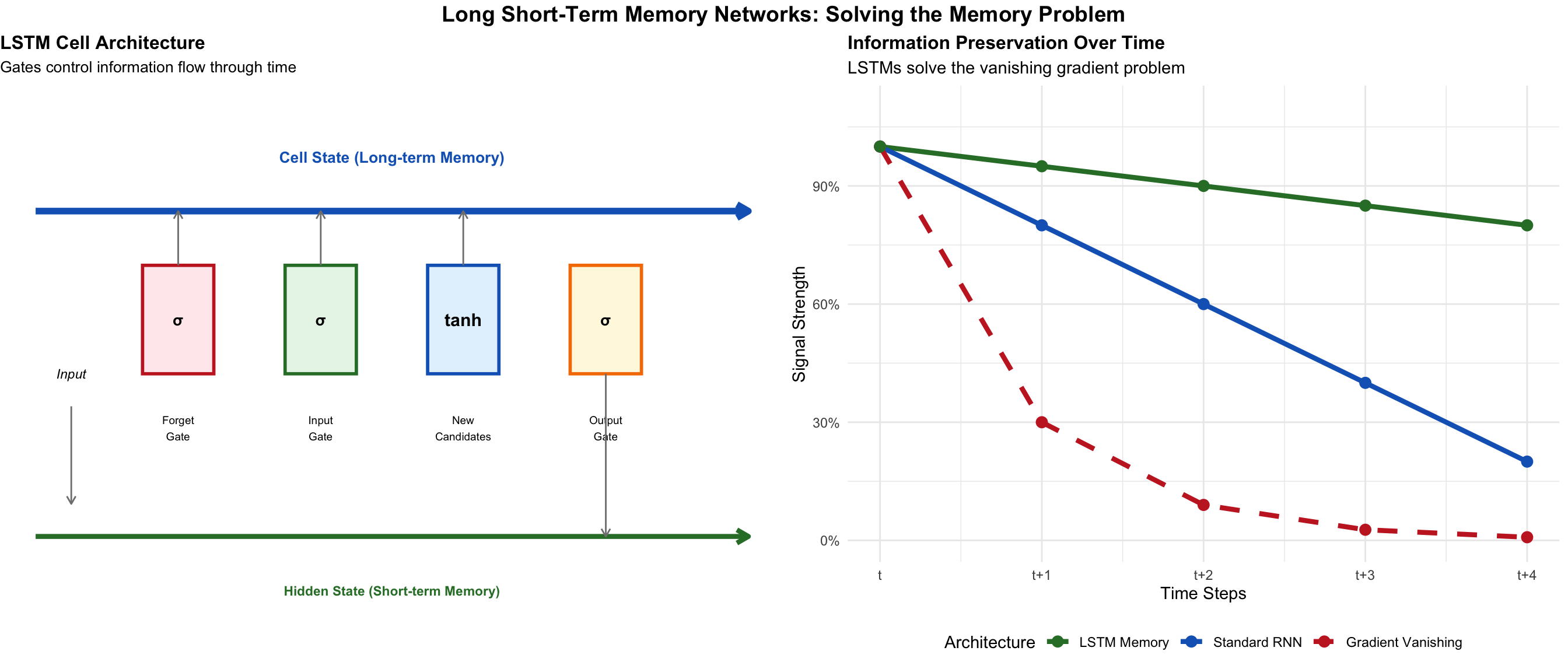
LSTM architecture: Three gates (forget, input, output) control information flow, allowing networks to remember important information for hundreds of time steps.
The LSTM Revolution (1997)
Sepp Hochreiter was Jürgen Schmidhuber’s PhD student in Munich. His thesis was radical: don’t fight the vanishing gradient - engineer around it.
The Long Short-Term Memory (LSTM) network was like a computer memory cell built from neurons. It had gates - neural circuits that decided what to remember, what to forget, and what to output. The key innovation was the “cell state” - a highway that let information flow unchanged across time. Gradients could flow backward along this highway without vanishing.
It was complicated - three gates, four neural networks inside each cell. Critics called it baroque. But it worked. LSTMs could remember for hundreds of time steps. They could learn when to store information, when to access it, when to forget it.
For the next twenty years, until transformers arrived, LSTMs were how we did language AI. Google Translate, Siri, Alexa - all ran on LSTMs.
Part IV: The Statistical Learning Era (1999-2011)
The late 1990s exposed an uncomfortable reality: neural networks, despite their biological inspiration and recent revival, were being systematically outperformed by methods with stronger theoretical foundations.
Consider the empirical evidence from that era. At KDD Cup 1999, the premier data mining competition, the top 10 submissions all used decision trees or rule-based systems. In bioinformatics, SVMs achieved 99% accuracy on protein classification while neural networks struggled to break 85%. The pattern repeated across domains: document classification, credit scoring, medical diagnosis. Neural networks had become a cautionary tale about the gap between biological metaphor and practical engineering.
The fundamental issue wasn’t theoretical - it was infrastructural. Neural networks demanded three preconditions that simply didn’t exist: 1. Data abundance: Networks needed millions of examples; we had thousands 2. Computational density: Backpropagation required matrix operations that CPUs handled poorly 3. Architectural knowledge: The space of possible architectures was vast and we were navigating blind
Until this trinity aligned, statistical methods offered a superior value proposition: theoretical guarantees, computational efficiency, and interpretable decisions.
Statistical Learning and Ensemble Methods
During the late 90s and early 2000s, while deep learning was still struggling, more traditional statistical methods dominated.
Support Vector Machines: Maximum Margin Classification
Vladimir Vapnik’s SVMs (1995) approached classification with geometric elegance: find the hyperplane that maximizes the margin between classes.
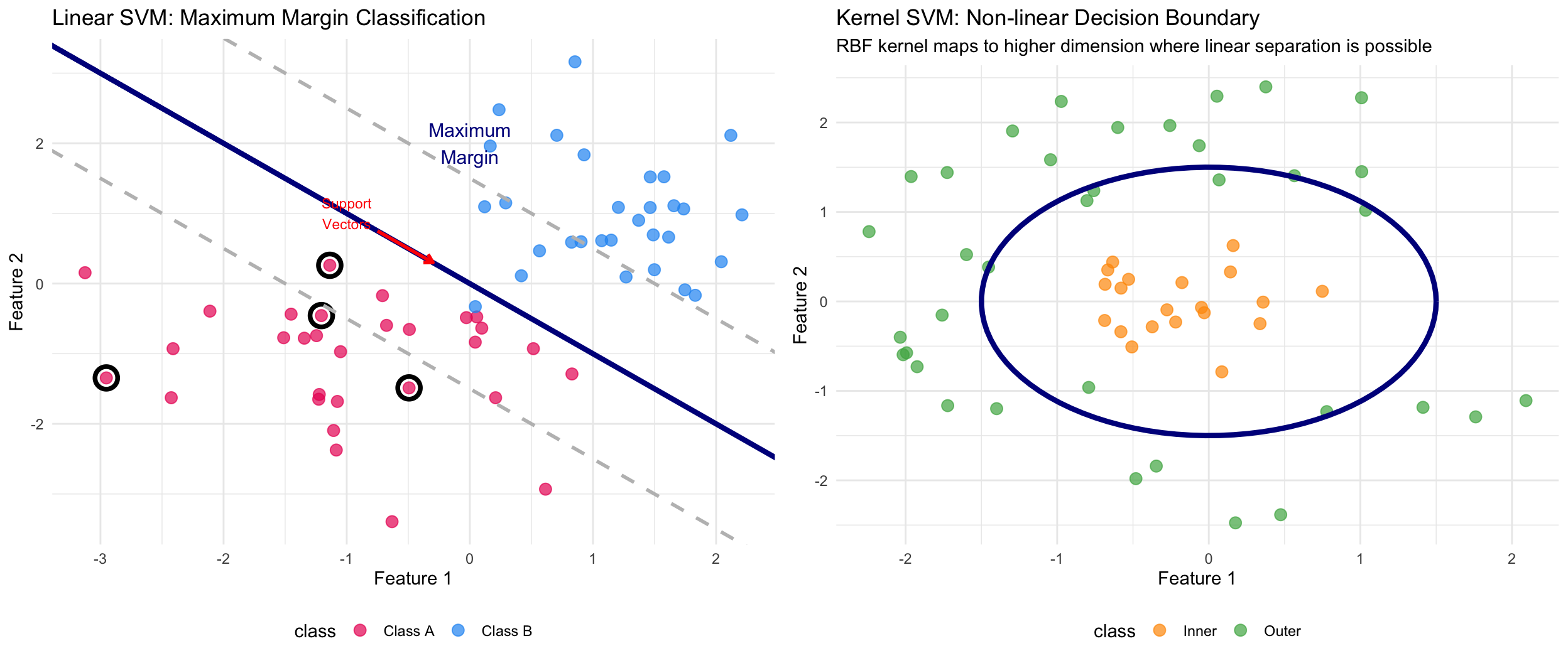
The kernel trick was the key insight: instead of explicitly mapping data to higher dimensions, compute dot products in that space using kernel functions: - Linear kernel: K(x,y) = x·y - RBF kernel: K(x,y) = exp(-γ||x-y||²) - Polynomial kernel: K(x,y) = (x·y + c)^d
Decision Trees: Learning by Splitting (CART - 1984)
Before Random Forests, we need to understand CART (Classification and Regression Trees), developed by Leo Breiman and colleagues. CART is a fundamental example of supervised learning - the algorithm learns patterns from labeled training data to make predictions on new data.
How CART Learns from Data:
- Start with all data at the root node
- Find the best split: For each variable, test all possible split points
- For classification: Minimize Gini impurity or entropy
- For regression: Minimize variance in child nodes
- Choose the variable and split point that creates the “purest” child nodes
- Recursively split each child node using the same process
- Stop when: Nodes are pure, too few samples, or max depth reached
The Learning Process Example:
Imagine predicting if someone will default on a loan: - First split: Income < $50K? (Biggest variance reduction) - Left branch: 80% default rate → Keep splitting - Right branch: 20% default rate → Keep splitting - Second split (left): Credit Score < 600? - Left: 95% default → Stop (pure enough) - Right: 60% default → Keep splitting - Continue until all leaves are reasonably pure
 A real CART decision tree: Each split maximizes information gain, creating a flowchart for predictions. New data follows the learned path to a prediction.
A real CART decision tree: Each split maximizes information gain, creating a flowchart for predictions. New data follows the learned path to a prediction.
Following a New Instance: Once trained, prediction is simple: 1. Start at root with new data point 2. Follow branches based on feature values 3. Arrive at leaf node with prediction 4. Output: Class probability or regression value
CART’s Strengths: - Interpretable: You can see exactly why a decision was made - No scaling needed: Works with raw features - Handles non-linear patterns: Through recursive splitting - Fast inference: Just follow the path
CART’s Weaknesses: - Overfitting: Trees memorize training data - Instability: Small data changes → completely different tree - Bias: Always splits on strongest predictor first - Limited expressiveness: Axis-aligned splits only
Random Forests: The Wisdom of Trees
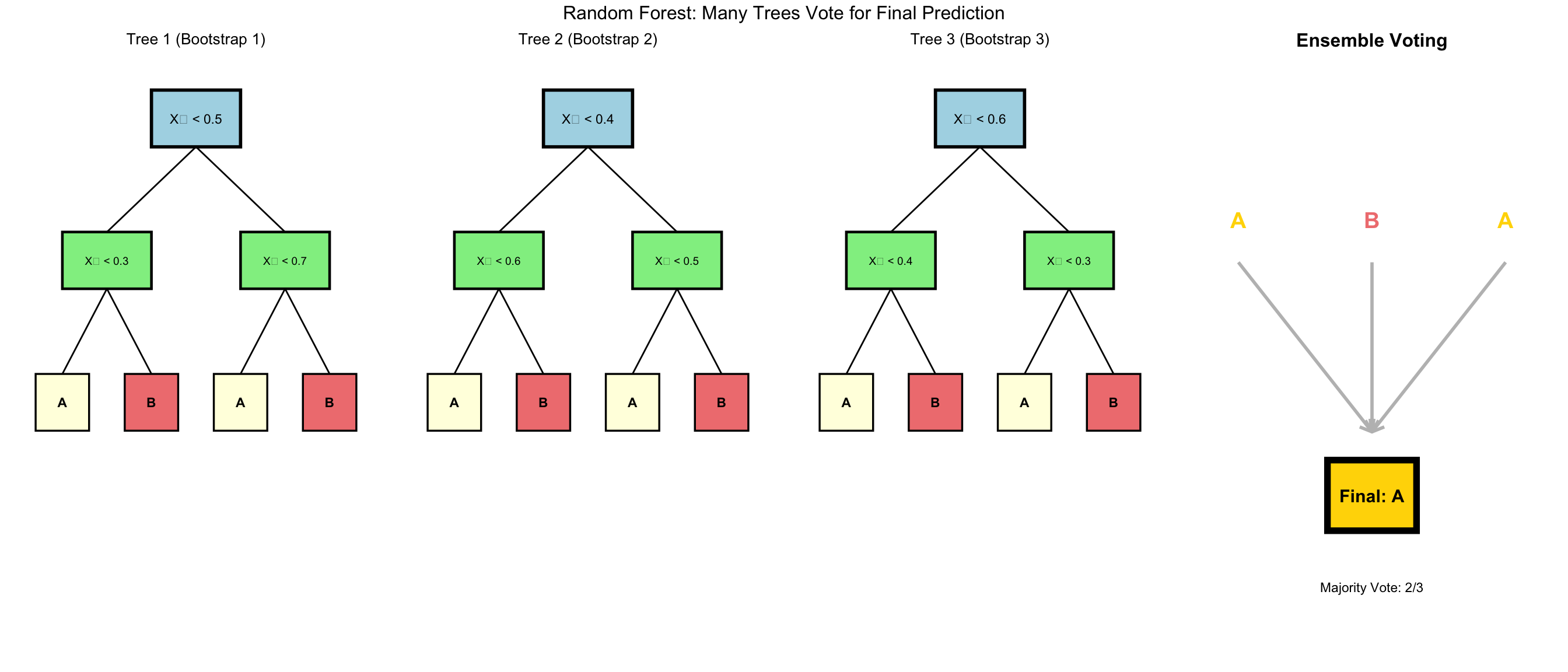
Leo Breiman’s insight (2001): What if we train many trees and let them vote? But there’s a problem - if all trees see the same data with all features, they’ll all make the same splits. The solution was brilliant:
Two Key Innovations:
- Bagging (Bootstrap Aggregating):
- Each tree gets a random sample of rows (with replacement)
- Different trees see different training examples
- Reduces overfitting through averaging
- Random Feature Selection (The Critical Innovation):
- Each tree only gets access to a random subset of columns/features
- At each split, only consider √(total features) for classification
- This is the key: Trees literally cannot see all variables
- Forces each tree to find patterns using different feature combinations
Why Column Restriction Is Revolutionary:
Imagine you have 100 features, and “Income” always dominates: - Traditional approach: Every tree splits on “Income” first → similar trees - Random Forest: - Tree 1 gets features [Age, Education, ZIP, …] - no Income! - Tree 2 gets features [Income, Gender, Credit Score, …] - Tree 3 gets features [Employment, Debt, Region, …] - no Income!
Result: Each tree must learn different patterns because they literally can’t access the same features. Tree 1 might discover Age+Education patterns, Tree 3 finds Employment+Debt relationships.
The Ensemble Magic: - 100 trees, each seeing different column subsets - Each tree: 60-70% accurate with its limited view - Combined: 85-95% accurate - the collective sees all patterns - Why it works: Different trees make different errors - Voting averages out individual tree mistakes
The Statistical Learning Toolkit
By 2010, machine learning had become a toolkit of specialized methods: - SVMs for maximum margin classification - Random Forests for anything with structured/tabular data
- Gradient Boosting for competition-winning accuracy - Logistic Regression when you needed interpretability - k-Nearest Neighbors for local patterns
Neural networks? They were the weird kid in the corner, theoretically powerful but practically useless. Too hard to train, too easy to overfit, too computationally expensive.
But three things were about to change everything.
Optimization and Regularization Advances (2012-2016)
The deep learning revolution required more than just architectural innovations - it needed better ways to train these increasingly complex networks. Several key techniques emerged during this period that became standard practice.
The Adam optimizer, introduced by Kingma and Ba in 2015, combined the benefits of AdaGrad’s adaptive learning rates with RMSProp’s moving averages of squared gradients. By maintaining separate learning rates for each parameter based on first and second moment estimates, Adam provided robust optimization across a wide range of problems without extensive hyperparameter tuning.
Batch normalization, developed by Sergey Ioffe and Christian Szegedy at Google in 2015, addressed the problem of internal covariate shift - the changing distribution of inputs to each layer during training. By normalizing inputs to have zero mean and unit variance, then learning scale and shift parameters, batch normalization allowed much deeper networks to train successfully and converged faster than previous approaches.
Dropout regularization, though introduced by Hinton’s team in 2012, became widely adopted during this period. By randomly deactivating neurons during training with typical probabilities of 0.5, networks learned redundant representations and reduced overfitting significantly - often improving accuracy by 2-3% on challenging datasets.
Data augmentation techniques provided another form of regularization. Simple transformations - random crops, horizontal flips, color jittering - could generate effectively infinite training data from finite datasets. Later techniques like Cutout (2017) and Mixup (2018) pushed this further, showing that even aggressive augmentations that created unrealistic images could improve generalization.
The Datasets that Enabled Progress
Progress in deep learning was as much about data as algorithms. Three datasets became particularly influential in driving the field forward.
MNIST, released by Yann LeCun in 1999, contained 70,000 handwritten digit images. Its moderate size - small enough to train on a laptop yet complex enough to be non-trivial - made it the standard benchmark for testing new ideas. Error rates on MNIST dropped from 12% in 1998 to 0.23% by 2012, tracking the field’s progress.
CIFAR-10 and CIFAR-100, created by Alex Krizhevsky in 2009, provided a harder challenge: 60,000 tiny 32×32 color images across 10 or 100 categories. The low resolution and diverse categories (animals, vehicles, objects) made this dataset ideal for testing architectural innovations without requiring massive computational resources.
ImageNet transformed computer vision research. Fei-Fei Li’s team spent three years creating a dataset of 14 million images across 22,000 categories, with labels provided by 49,000 workers on Amazon Mechanical Turk. The ImageNet Large Scale Visual Recognition Challenge (ILSVRC), using a subset of 1,000 categories and 1.2 million images, became the field’s primary benchmark. Error rates fell from 28.2% in 2010 to 3.57% in 2015, surpassing human performance of 5.1%.
Word Embeddings: Self-Supervised Learning Discovers Meaning (2013)
A crucial missing piece for language understanding was a better way to represent words. In 2013, Tomas Mikolov at Google created Word2Vec, demonstrating the power of self-supervised learning - the model learned meaningful representations without any labeled data, just raw text.
The breakthrough: Word2Vec predicted context words from a target word (Skip-gram) or vice versa (CBOW). This simple task - predicting nearby words - forced the model to learn that words appearing in similar contexts must have similar meanings. No human told it that “cat” and “dog” were related; it discovered this by observing they appear near words like “pet,” “furry,” and “walked.”
Through this self-supervised objective, Word2Vec learned dense vector representations where semantic relationships were captured geometrically. The famous example: vector('king') - vector('man') + vector('woman') resulted in a vector very close to vector('queen'). The model discovered that gender, royalty, geography, and countless other relationships could be encoded as consistent directions in vector space.
The Power of Self-Supervised Learning:
Word2Vec proved that you don’t need labeled data to learn meaning - just observe how words are used. By predicting context (self-supervised learning), the model discovered that semantic relationships are directions in space. The vector from “man” to “king” captures “royalty” - and this same vector transforms “woman” to “queen”, “prince” to “king”, universally.
Self-supervised learning revealed several fundamental properties of language. The model learned analogical relationships purely from observing word co-occurrences. “Paris” appeared in similar contexts to “France” as “Tokyo” did to “Japan” - from this pattern alone, the model inferred the capital-country relationship. No explicit labeling was required; the structure emerged from usage patterns.
The geometric nature of meaning became apparent through these embeddings. Words with similar usage clustered together in vector space - medical terms occupied one region, colors another, emotions yet another. This organization wasn’t programmed but emerged naturally from the training objective of predicting context words.
Vector arithmetic captured compositional semantics. Adding the vectors for “artificial” and “intelligence” produced a point near “AI,” “machine learning,” and “neural networks.” The model learned these relationships solely from observing how words co-occur in text.
This principle - that models could learn rich representations from data’s inherent structure rather than explicit labels - became foundational to modern NLP. BERT (2018) extended this with masked language modeling, predicting randomly hidden words from context. GPT models (2018-2024) learned by predicting the next word in sequences. CLIP (2021) aligned images with captions using contrastive learning on web data. These self-supervised approaches enabled training on vast unlabeled datasets, leading to the foundation models that now dominate the field.
The Hardware Revolution: GPUs and CUDA
The final piece of the puzzle was hardware. The complex matrix multiplications at the heart of neural networks were slow on CPUs. But in 2007, NVIDIA released CUDA, a parallel computing platform that allowed researchers to harness the power of Graphics Processing Units (GPUs) for general-purpose computing. GPUs, designed to render pixels in parallel for video games, turned out to be perfectly suited for the parallel nature of neural networks, providing a 50-100x speedup.
The Deep Learning Prerequisites (2006-2011)
Several developments between 2006 and 2011 laid the groundwork for deep learning’s breakthrough.
Geoffrey Hinton’s 2006 paper on Deep Belief Networks introduced layer-wise pretraining. By training each layer as a restricted Boltzmann machine before fine-tuning the entire network, Hinton showed that networks with seven or more layers could be trained successfully. This addressed the vanishing gradient problem that had limited neural networks to shallow architectures.
The introduction of ReLU (Rectified Linear Unit) activation by Nair and Hinton in 2010 provided another key advance. The function, simply max(0, x), avoided the saturation problems of sigmoid and tanh activations. Networks using ReLU trained approximately six times faster and maintained gradient flow through many layers, enabling the training of much deeper architectures.
GPU computing transformed the computational landscape. Andrew Ng’s team at Stanford demonstrated in 2009 that consumer graphics cards could accelerate neural network training by factors of 50-100x compared to CPUs. NVIDIA’s CUDA platform, released in 2007, made these graphics processors programmable for general computation, turning gaming hardware into powerful tools for machine learning.
The availability of large-scale datasets completed the picture. ImageNet provided three orders of magnitude more labeled images than previous benchmarks like CIFAR-10. The internet offered vast quantities of text, images, and other data. These large datasets were essential - neural networks required extensive training data to learn effective representations.
The Breakthrough: AlexNet (2012)
On September 30, 2012, all the pieces came together. At the ILSVRC, a team from the University of Toronto led by Geoffrey Hinton with his students Alex Krizhevsky and Ilya Sutskever submitted AlexNet.
The competition had been dominated by hand-crafted features - SIFT, HOG, Fisher Vectors. The best teams had plateaued around 26% error for two years. AlexNet achieved a major improvement:
022 15.3% error rate (vs 26.2% runner-up) - a 41% relative improvement 022 60 million parameters trained on 1.2 million images 022 5 convolutional layers + 3 fully connected 022 Trained on 2 GTX 580 GPUs for a week (would’ve taken 3 weeks on CPU)
The secret sauce: 022 ReLU activation: 6x faster than tanh, no vanishing gradients 022 Dropout (0.5): Randomly zero neurons, reducing overfitting by 2% 022 Data augmentation: 224x224 crops from 256x256 images, horizontal flips, color jittering - 2048x more training data 022 Local Response Normalization: Lateral inhibition inspired by neurobiology (later abandoned)
The margin of victory was so large that organizers asked Krizhevsky to verify his submission. The following year, nearly every top entry used deep learning. After decades of incremental progress, the field had transformed overnight.
Architectural Innovations (2014-2016)
The years following AlexNet saw rapid experimentation with network architectures, each addressing specific limitations of previous designs.
VGGNet, developed at Oxford in 2014 by Karen Simonyan and Andrew Zisserman, demonstrated that architectural simplicity could be effective. Using only 3×3 convolutional filters stacked to depths of 16-19 layers, VGG showed that very deep networks with small filters could achieve excellent performance. The architecture achieved 7.3% error on ImageNet while being conceptually straightforward.
GoogLeNet (also called Inception), developed by Google in 2014, took a different approach. Christian Szegedy’s team introduced “Inception modules” that computed multiple convolution sizes (1×1, 3×3, 5×5) in parallel, allowing the network to capture features at different scales simultaneously. This architecture reached 22 layers deep while using 12 times fewer parameters than AlexNet, winning the 2014 ILSVRC with 6.7% error.
ResNet, introduced by Kaiming He and colleagues at Microsoft Research in 2015, solved the degradation problem in very deep networks through skip connections. By adding the input of a layer directly to its output, gradients could flow unimpeded through the network. This simple modification enabled training of networks with 152 layers that achieved 3.57% error on ImageNet, surpassing human performance at 5.1%.
DenseNet, proposed in 2017, extended the skip connection idea by connecting each layer to all subsequent layers. This dense connectivity pattern promoted feature reuse and gradient flow while requiring fewer parameters than comparable architectures.
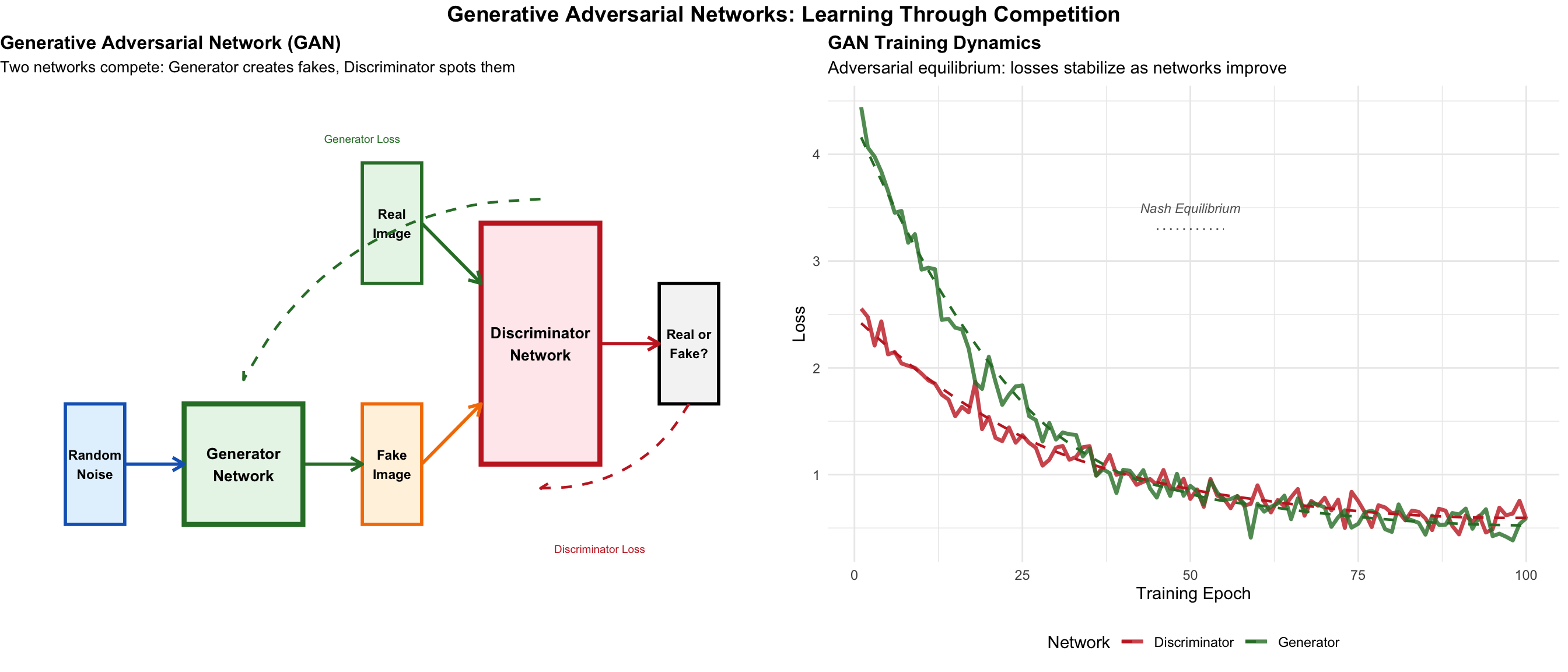
GANs: A minimax game where the Generator learns to fool the Discriminator, while the Discriminator learns to spot fakes. This adversarial training produces remarkably realistic synthetic data.
In 2014, Ian Goodfellow, then a PhD student, invented Generative Adversarial Networks (GANs). This was a novel approach to training generative models, pitting a Generator (which creates fake images) against a Discriminator (which tries to spot the fakes) in a minimax game. The result was a stunning leap in the realism of AI-generated images.
The Representation Learning Revolution
When researchers looked inside trained networks, they found something interesting. Early layers learned simple features (edges, colors). Middle layers combined these into parts (eyes, wheels). Deep layers represented complete concepts (faces, cars).
Brandon Rohrer’s excellent visual explanation of CNNs
Andrej Karpathy’s Stanford CS231n lecture on CNNs - a masterclass in computer vision
The network had discovered the hierarchical structure of the visual world - without being told it existed.
This suggested an important principle: intelligence might emerge from learning good representations of the world.
Part V: The Deep Learning Revolution (2012-2016)
September 30, 2012. 3:47 PM.
The ImageNet competition leaderboard updated. The computer vision community collectively gasped. A team from the University of Toronto - not Stanford, not MIT, not Google - had just posted a 15.3% error rate. The previous best was 26.2%. This wasn’t an improvement; it was a demolition.
Geoffrey Hinton, the neural network researcher everyone thought was stuck in the past, had just changed the future.
The Convergence of Three Miracles (2006-2012)
Looking back at the machine learning landscape of the 2000s, the signs of change were accumulating. Three independent developments were converging toward an inflection point.
For neural networks to compete with statistical methods, three developments needed to align. Between 2006 and 2012, they did.
Data Availability
The internet provided unprecedented amounts of labeled data. Suddenly we had billions of labeled images on Flickr, countless hours of transcribed speech on YouTube, and the entire web’s text to train on. Fei-Fei Li spent three years building ImageNet014 14 million images, hand-labeled using Amazon Mechanical Turk. It cost hundreds of thousands of dollars. It would prove to be worth billions.
Computational Hardware
In 2007, NVIDIA released CUDA, letting researchers program graphics cards for general computation. GPUs were built for video games014calculating millions of pixels in parallel. Turns out, neural networks are the same thing: millions of parallel matrix multiplications. A $500 gaming GPU could outperform a $10,000 CPU cluster. Andrew Ng proved it in 2009, training networks 70x faster on GPUs.
Algorithmic Improvements
Researchers discovered a collection of “tricks” that suddenly made deep networks trainable:
ReLU (2010): Everyone used sigmoid activations because they looked biological. But they had a fatal flaw014gradients vanished. The fix was embarrassingly simple: f(x) = max(0, x). Just return zero for negative inputs, x for positive. No saturation, no expensive exponentials. Networks trained 6x faster.
Dropout (2012): Geoff Hinton’s idea was insane: randomly delete half your neurons during training. His student Nitish Srivastava implemented it. It worked brilliantly014forcing the network to be robust, no single neuron could dominate. Overfitting dropped by 50%.
Better Initialization (2010): Xavier Glorot realized weight initialization was critical. Too small: gradients vanish. Too large: gradients explode. Scale by 1/√n where n is the number of inputs. One line of code that made 10-layer networks suddenly trainable.
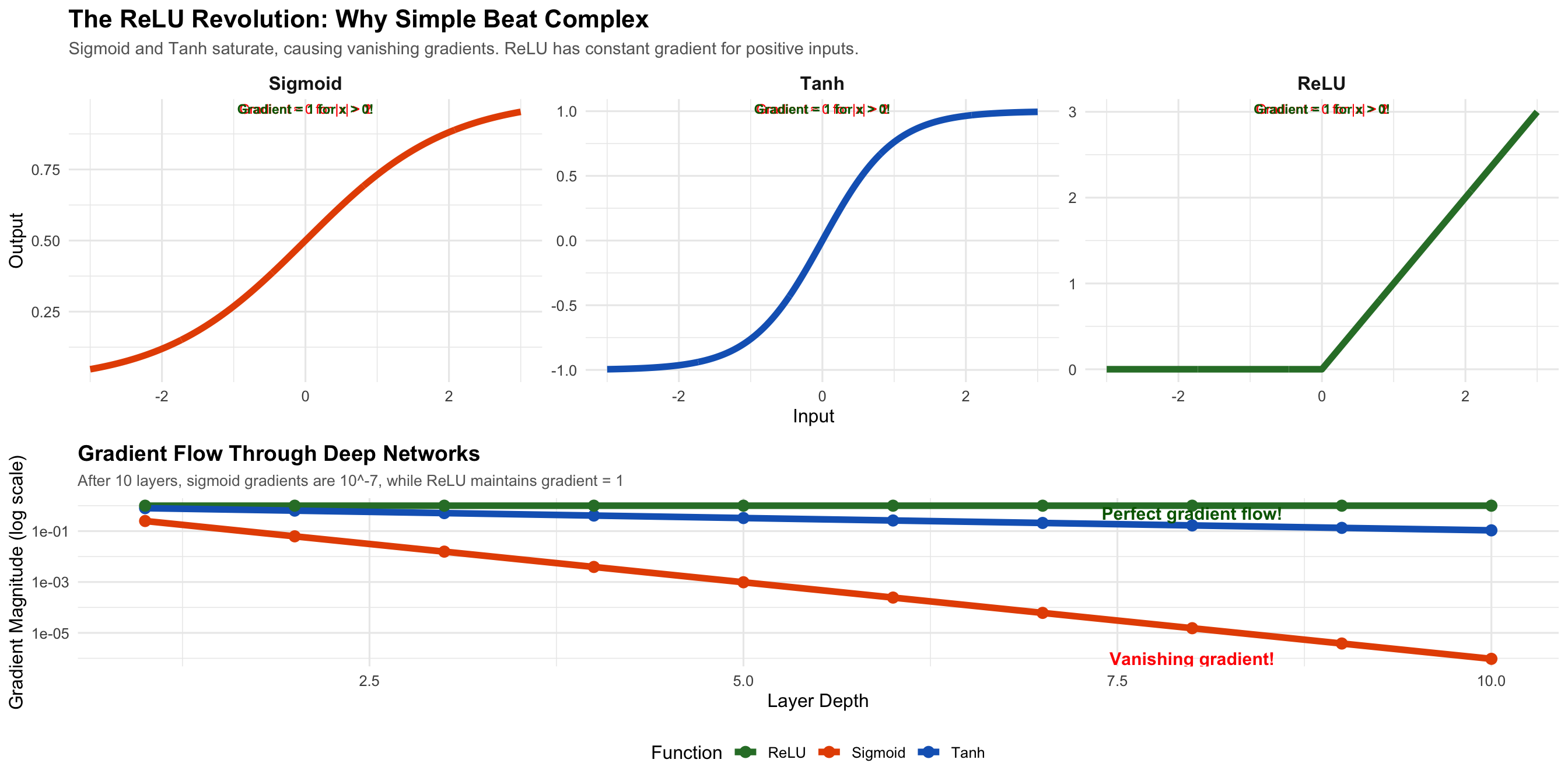
ReLU’s simplicity was its genius. While Sigmoid and Tanh suffer from vanishing gradients in deep networks, ReLU maintains constant gradient flow, enabling training of much deeper architectures.
AlexNet and the ImageNet Competition (2012)
On September 30, 2012, the ImageNet Large Scale Visual Recognition Challenge results were announced. Geoffrey Hinton’s team from the University of Toronto - Alex Krizhevsky, Ilya Sutskever, and Hinton himself - submitted a convolutional neural network they called AlexNet.
The previous state-of-the-art methods relied on hand-crafted features like SIFT (Scale-Invariant Feature Transform), HOG (Histogram of Oriented Gradients), and Fisher Vectors. These approaches had plateaued around 26% error rate for two years. AlexNet achieved 15.3% error - a relative improvement of 41% over the 26.2% second-place result.
AlexNet’s architecture consisted of five convolutional layers followed by three fully connected layers, totaling 60 million parameters. The network was trained on 1.2 million ImageNet images using two GTX 580 GPUs over the course of a week - a task that would have taken approximately three weeks on contemporary CPUs.
Several technical choices contributed to AlexNet’s success. ReLU activations enabled faster training and better gradient flow compared to traditional sigmoid or tanh functions. Dropout with probability 0.5 in the fully connected layers reduced overfitting. Data augmentation - extracting random 224×224 patches from 256×256 images, applying horizontal flips, and adding color jittering - effectively increased the training set size. The use of GPUs provided the computational power necessary for training such a large network.
This result marked a fundamental shift in computer vision. Within a year, nearly all competitive entries to computer vision challenges used deep convolutional networks. The era of manual feature engineering in vision had ended.

Dropout forces the network to be robust by randomly removing neurons during training. No single neuron can dominate - the network must learn redundant representations.
Architectural Innovations (2014-2016)
The years following AlexNet saw rapid experimentation with network architectures, each addressing specific limitations of previous designs.
VGGNet, developed at Oxford in 2014 by Karen Simonyan and Andrew Zisserman, demonstrated that architectural simplicity could be effective. Using only 3×3 convolutional filters stacked to depths of 16-19 layers, VGG showed that very deep networks with small filters could achieve excellent performance. The architecture achieved 7.3% error on ImageNet while being conceptually straightforward.
GoogLeNet (also called Inception), developed by Google in 2014, took a different approach. Christian Szegedy’s team introduced “Inception modules” that computed multiple convolution sizes (1×1, 3×3, 5×5) in parallel, allowing the network to capture features at different scales simultaneously. This architecture reached 22 layers deep while using 12 times fewer parameters than AlexNet, winning the 2014 ILSVRC with 6.7% error.
ResNet, introduced by Kaiming He and colleagues at Microsoft Research in 2015, solved the degradation problem in very deep networks through skip connections. By adding the input of a layer directly to its output, gradients could flow unimpeded through the network. This simple modification enabled training of networks with 152 layers that achieved 3.57% error on ImageNet, surpassing human performance at 5.1%.
DenseNet, proposed in 2017, extended the skip connection idea by connecting each layer to all subsequent layers. This dense connectivity pattern promoted feature reuse and gradient flow while requiring fewer parameters than comparable architectures.
Part VI: The Attention Revolution (2017-2020)
Sequential models faced inherent limitations with long-range dependencies and contextual reasoning. The Winograd Schema Challenge illustrated this problem: resolving the pronoun “it” in “The animal didn’t cross the street because it was too tired” versus “The animal didn’t cross the street because it was too wide” requires understanding semantics and world knowledge, not just syntax. Recurrent Neural Networks, even with LSTM gates, struggled with such relationships as information had to pass through many sequential steps.
RNNs processed text one word at a time, maintaining a hidden state that theoretically captured all previous context. In practice, this sequential processing created an information bottleneck. CNNs could process multiple positions simultaneously but were limited to local receptive fields. The alternative was to allow every position in a sequence to directly attend to every other position.
Attention Is All You Need (2017)
In June 2017, Vaswani et al. from Google Brain published “Attention Is All You Need”, introducing the Transformer architecture. The paper demonstrated that attention mechanisms alone, without recurrence or convolution, could achieve state-of-the-art results in machine translation.
Grant Sanderson (3Blue1Brown) provides an exceptional visual explanation of attention mechanisms
Understanding Attention: The Core Innovation
The Problem: RNNs process sequences step-by-step, making them slow and unable to capture long-range dependencies effectively. CNNs have limited receptive fields. How can we let every position in a sequence directly interact with every other position?
The Solution: Attention mechanisms compute a weighted average of all positions, where the weights are learned based on content similarity.
The Mathematics of Attention
The attention mechanism computes three learned linear projections for each input:
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]
Where: - Q (Query): What information am I looking for? (What does “cat” need to know?) - K (Key): What information do I contain? (What can each word provide?) - V (Value): The actual information to aggregate (The content to use) - \(\sqrt{d_k}\): Scaling factor to prevent gradient vanishing in softmax
Why This Works:
- Parallelization: Unlike RNNs, all positions can be processed simultaneously
- Direct connections: Any position can directly attend to any other position
- Learned importance: The model learns what to pay attention to for each task
- Multiple perspectives: Multi-head attention captures different types of relationships
Understanding the complete Transformer architecture
The Transformer Architecture
The Transformer combines self-attention with: - Positional encodings: Since attention has no inherent order, we add sinusoidal position information - Layer normalization: Stabilizes training of deep networks - Residual connections: Allows gradient flow through deep architectures - Feed-forward networks: Adds non-linear transformations between attention layers
This architecture enabled a new paradigm: massive self-supervised pre-training followed by task-specific fine-tuning.
ELMo: Deep Contextualized Word Representations
Peters et al. (2018) from Allen AI showed that deep, bidirectional language models could learn rich word representations. Unlike Word2Vec’s static embeddings, ELMo created different representations for “bank” in “river bank” vs “bank account.”
GPT-1: Unsupervised Pre-training
OpenAI’s GPT (June 2018) used a Transformer decoder to predict the next word on BookCorpus (7,000 unpublished books). The key insight: unsupervised pre-training followed by supervised fine-tuning significantly improved performance on downstream tasks.
BERT: Bidirectional Understanding
Google’s BERT (October 2018) introduced a breakthrough: Masked Language Modeling (MLM).
The Problem: GPT could only read left-to-right. But language has bidirectional context.
The Solution:
 Masked language modeling: BERT learns by predicting randomly masked words from bidirectional context, creating rich representations without labeled data.
Masked language modeling: BERT learns by predicting randomly masked words from bidirectional context, creating rich representations without labeled data.
- Randomly mask 15% of tokens
- Predict masked tokens from bidirectional context
- 80% of time: replace with [MASK]
- 10% of time: replace with random token
- 10% of time: keep unchanged
This forces the model to: - Use bidirectional context (can’t just copy) - Be robust to noise (random replacements) - Maintain distributional consistency (unchanged tokens)
Results: BERT achieved SOTA on 11 NLP tasks. More importantly, it learned rich representations that could be fine-tuned for any task with minimal data.
The Scaling Hypothesis (2019-2020)
While Google focused on architecture improvements, OpenAI bet on scale. Their GPT series just predicted the next word - but did it on massive amounts of text with increasingly large models:
- GPT-1 (2018): 117M parameters, 4.5GB of text
- GPT-2 (2019): 1.5B parameters, 40GB of text (WebText)
- GPT-3 (2020): 175B parameters, 570GB of text (CommonCrawl + books + Wikipedia)
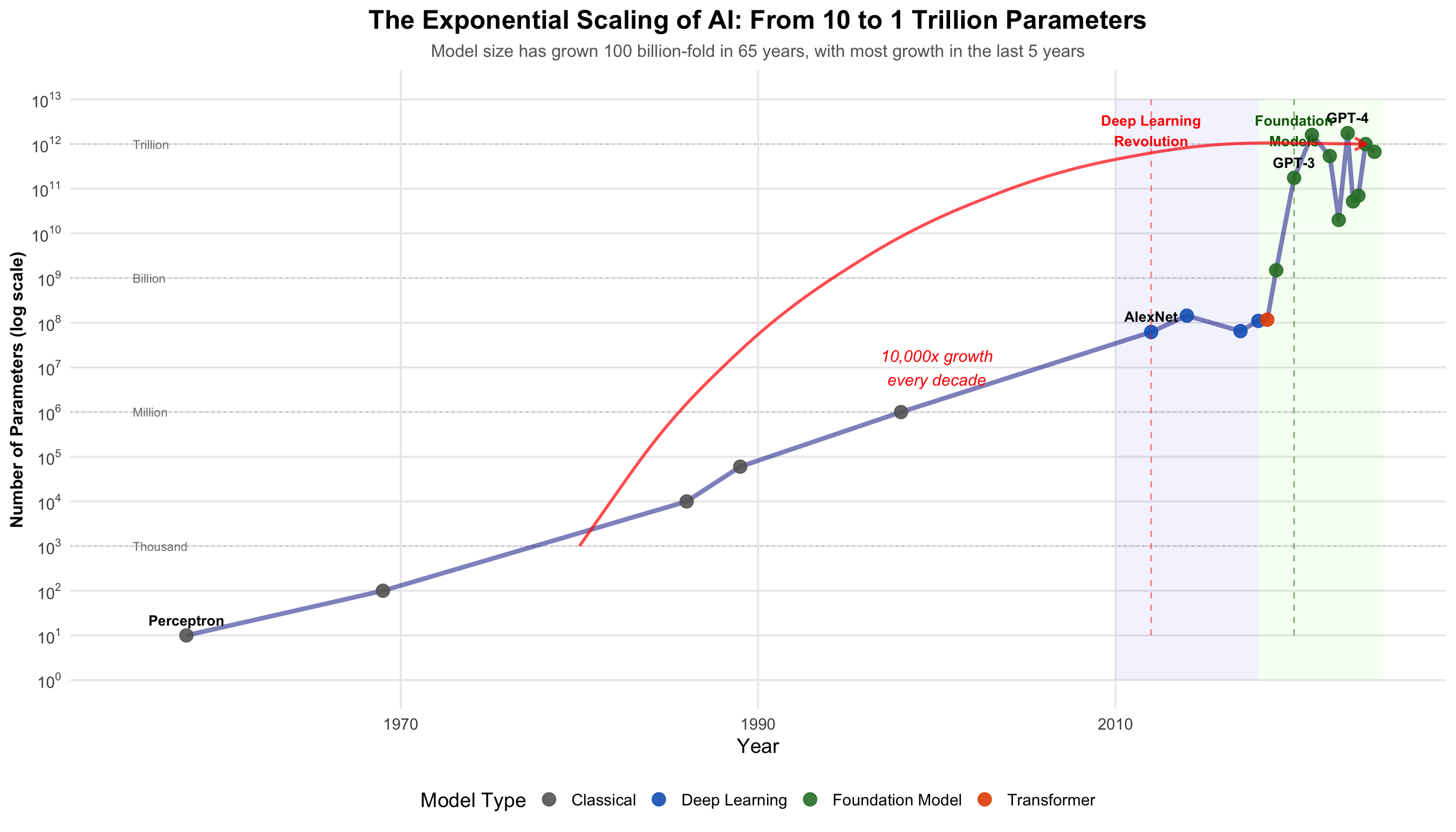
Model size has grown in distinct phases: slow growth in the classical AI era, steady increase during deep learning, and rapid scaling in recent years. GPT-4’s 1.76 trillion parameters would have seemed unlikely just 5 years earlier.
GPT-2: Dangerous Capabilities
In February 2019, OpenAI announced GPT-2 with unusual fanfare - and controversy. They initially refused to release the full model, citing concerns about malicious use. The 1.5B parameter model could generate coherent, multi-paragraph text that was often indistinguishable from human writing.
GPT-3: Emergent Intelligence
GPT-3’s training gives a sense of the scale involved: - Cost: ~$4.6 million in compute - Training time: 34 days on 10,000 V100 GPUs - Energy: 1,287 MWh (enough to power 120 US homes for a year) - Data: 300 billion tokens (roughly 500 billion words) - Architecture: 96 layers, 96 attention heads, 12,288 dimensional states
The model exhibited emergent abilities that weren’t explicitly programmed: - Three-digit arithmetic: Emerged around 13B parameters - Analogical reasoning: Emerged around 50B parameters
- Code generation: Emerged around 100B parameters - Few-shot learning: Could learn new tasks from 1-10 examples
Most remarkably, GPT-3 showed in-context learning - it could learn new patterns during inference without updating weights. Show it a few examples of English→French translation, and it would translate. Show it math problems with solutions, and it would solve new ones.
The Scaling Laws: Kaplan et al. (2020) discovered predictable relationships:
Loss = A / (N^α × D^β × C^γ)Where N = parameters, D = data, C = compute. Performance improved predictably with scale - until emergent capabilities appeared suddenly, like phase transitions.
The model had learned to perform complex reasoning tasks simply by predicting the next word in internet text. This raised an interesting question: how much of intelligence emerges from pattern recognition at sufficient scale?
Part VII: The Foundation Model Era (2021-Present)
The scaling hypothesis - initially dismissed as brute force engineering - turned out to reveal something important. Beyond certain thresholds of scale, new capabilities appear discontinuously. These aren’t incremental improvements but something more like phase transitions: arithmetic emerging at 10B parameters, chain-of-thought reasoning at 60B, theory of mind at 150B. It’s still not clear exactly why this happens.
GPT-3 was trained to predict the next word. That’s it. But somewhere around 175 billion parameters, it learned to code, translate languages it was never explicitly taught, solve math problems, and write poetry. This is emergence - when quantity becomes quality in ways we can’t predict.
How Large Language Models store and retrieve factual knowledge
The Cambrian Explosion
Post-GPT-3, AI development exploded. Every major tech company and dozens of startups raced to build foundation models:
 Comparison of leading foundation models across key capabilities: reasoning, coding, multimodal understanding, and context length.
Comparison of leading foundation models across key capabilities: reasoning, coding, multimodal understanding, and context length.
Multimodal Intelligence (2021-2022)
The success of transformers in language raised an uncomfortable question for computer vision researchers: Were CNNs actually necessary? For a decade, convolutional neural networks had dominated vision tasks. Their architecture encoded a powerful assumption - that visual features are local and hierarchical. Edges combine into textures, textures into parts, parts into objects.
The question was whether that assumption was limiting performance.
Vision Transformers
Alexey Dosovitskiy’s team at Google Brain tried something that seemed overly simple: chopping up images into squares and feeding them to a transformer like words.
Images aren’t text - they lack grammar, syntax, and sequential structure. A patch of blue pixels could be sky, water, or a shirt. Context matters differently than in language.
But when they trained their Vision Transformer (ViT) on 14 million images, it worked - and beat CNNs when given enough data. The key insight: spatial relationships in images can be modeled as sequences.
![]()
Vision Transformer splits images into patches, treating them as sequences similar to words in NLP, enabling powerful transfer learning from language models.
The Vision Transformer architecture follows a straightforward approach: images are divided into 16×16 pixel patches, each flattened and projected into a 768-dimensional vector. These patch embeddings receive positional encodings to maintain spatial information, similar to how transformers handle word position in sentences. A learnable classification token is prepended to the sequence, and the entire set of patches is processed through standard transformer layers.
This approach succeeds because images contain long-range dependencies - features in one part of an image often relate to features in distant parts. While convolutional networks build up receptive fields gradually through layers, transformers can immediately attend to any patch from any other patch, capturing global relationships from the first layer.
Masked Image Modeling: Self-Supervised Learning for Vision
In November 2021, Kaiming He and his team at Facebook AI Research applied BERT’s masked language modeling approach to computer vision. Their Masked Autoencoders (MAE) trained vision models by randomly masking 75% of an image’s patches and training the model to reconstruct the missing regions.
This high masking ratio - much higher than the 15% typically used in language models - forced the model to understand global image structure rather than simply interpolating from nearby patches. Models trained this way learned comprehensive visual representations: they captured object structure, lighting patterns, texture continuity, and spatial relationships without requiring labeled data.
CLIP: Connecting Vision and Language
In January 2021, OpenAI introduced CLIP (Contrastive Language-Image Pre-training), which learned visual concepts from natural language supervision. Rather than training on manually labeled datasets, CLIP used 400 million image-text pairs collected from the internet.
The training approach used contrastive learning: given a batch of images and their corresponding text descriptions, the model learned to encode both modalities such that matched pairs had high similarity while unmatched pairs had low similarity. The vision encoder (either a ResNet or Vision Transformer) and text encoder (a Transformer) were trained jointly to project both modalities into a shared embedding space.
This approach enabled zero-shot transfer to downstream tasks. Without any task-specific training, CLIP achieved 76% accuracy on ImageNet classification - comparable to a ResNet-50 trained specifically on ImageNet. The model could classify images by comparing their embeddings to text embeddings of class descriptions like “a photo of a [class name].”
CLIP demonstrated that visual representations could be learned from natural language supervision at scale. The shared embedding space it created, where visual and textual concepts were aligned, became foundational for subsequent developments in text-to-image generation, visual question answering, and multimodal understanding.
Diffusion Models: A New Approach to Generation
Diffusion models introduced a fundamentally different approach to image generation. Rather than learning to generate images directly, they learned to reverse a gradual noising process. Starting with a clean image, the forward process progressively adds Gaussian noise over many steps until the image becomes pure noise. The model then learns to reverse this process, denoising step by step to recover the original image.
Stable Diffusion, released by Stability AI in 2022, made this approach practical for widespread use. By operating in a compressed latent space (typically 64×64) rather than pixel space (512×512), it reduced computational requirements by roughly 50x. Text conditioning was achieved through cross-attention layers that incorporated CLIP text embeddings at multiple scales throughout the denoising network. This architecture enabled high-quality text-to-image generation on consumer GPUs with 8GB of VRAM, democratizing access to powerful generative models.
ChatGPT and the Transformation of AI Interaction (November 2022)
On November 30, 2022, OpenAI released ChatGPT as a research preview. The model itself - a fine-tuned version of GPT-3.5 - wasn’t dramatically more capable than previous releases. What changed was the interface and training approach.
ChatGPT’s adoption broke all previous records. It reached one million users in five days, compared to Instagram’s 2.5 months. Within two months, it had 100 million users - a milestone that took TikTok nine months. By its first anniversary, ChatGPT had been integrated into Microsoft Office and adopted by approximately 40% of Fortune 500 companies.
The Role of Reinforcement Learning from Human Feedback (RLHF)
ChatGPT’s key innovation was the systematic application of Reinforcement Learning from Human Feedback (RLHF) to align the model with human preferences. The process involved three phases:
First, supervised fine-tuning created an initial instruction-following model. Human contractors wrote high-quality responses to thousands of diverse prompts, covering creative writing, coding, factual questions, and ethical scenarios. This dataset trained the base GPT-3.5 model to follow instructions rather than simply complete text.
Second, a reward model was trained to predict human preferences. Contractors ranked multiple model outputs for each prompt, typically comparing 4-9 responses. These rankings trained a 6-billion parameter model to score outputs based on helpfulness, harmlessness, and honesty - the three H’s that became OpenAI’s alignment targets.
Third, Proximal Policy Optimization (PPO) fine-tuned the language model to maximize the reward model’s scores while maintaining similarity to the original model through KL divergence penalties. This constraint prevented the model from finding adversarial solutions that gamed the reward function while producing nonsensical outputs.
Why ChatGPT Succeeded When GPT-3 Didn’t
GPT-3 (2020) was capable, but harder to use: - GPT-3: Required careful prompting, gave inconsistent responses, lacked guardrails - ChatGPT: Conversational, more consistent, refused harmful requests, remembered context
The interface mattered. The chat format made AI feel like a collaborator rather than a tool. You could iterate, clarify, and push back.
Practical Applications
Non-technical users started experiencing what might be called cognitive augmentation: - Lawyers drafting contracts more quickly - Students getting help debugging code - Writers working through blocks - Doctors getting differential diagnosis suggestions
The conversation shifted from “AI can’t do my job” to “what parts of my job can AI do?” Knowledge work started to feel different. If a model could write, code, analyze, and reason, it raised questions about what parts of work would remain human.
The AI Competition Intensifies: 2023’s Major Releases
ChatGPT’s success kicked off significant competition. Every major tech company responded, startups raised substantial funding, and the pace of advancement accelerated considerably.
GPT-4: The Anticipated Leap (March 14, 2023)
GPT-4 had been in training since August 2022, using an estimated 25,000 A100 GPU-years. The improvements over GPT-3.5 were substantial:
Benchmark Performance: - Bar Exam: 90th percentile (GPT-3.5: 10th percentile) - Biology Olympiad: 99th percentile (GPT-3.5: 31st) - SAT Math: 700/800 (GPT-3.5: 590/800) - Codeforces: 1200 rating (expert level)
GPT-4 was multimodal from training, processing text and images in the same model. OpenAI held back vision capabilities for six months, citing safety concerns. When released, it could analyze charts, debug UIs from screenshots, and solve visual reasoning problems.
The context window expanded from 8K to 32K, then 128K tokens - enough to hold entire codebases or novels in memory. This transformed use cases: lawyers could analyze complete contracts, researchers could process entire papers, developers could debug whole applications.
Claude: The Safety-First Challenger (March 14, 2023)
Anthropic launched Claude the same day as GPT-4. Founded by ex-OpenAI safety researchers who left over disagreements about commercialization pace, Anthropic took a different approach.
Constitutional AI was their innovation: 1. Train a helpful, harmless, honest assistant 2. Use AI feedback (not just human) to identify problematic outputs 3. Train the model to critique and revise its own responses 4. Result: a model that self-censors without explicit filters
Claude’s 100,000 token context window, five times larger than GPT-4’s at the time, enabled processing of entire novels like “The Great Gatsby” in a single context. This made it particularly suitable for analyzing long documents, complex codebases, or maintaining extended conversations.
Google’s Response (March-December 2023)
Google’s Bard launch on March 21, 2023, faced immediate challenges. A factual error about the James Webb Space Telescope in the launch demo led to significant market reaction, with the company losing substantial market capitalization. As the organization that developed the transformer architecture, Google faced pressure to demonstrate leadership in the generative AI space.
The initial launch highlighted several organizational challenges. LaMDA, while technically capable, lagged behind GPT-4 in performance. Google’s emphasis on safety and careful deployment contrasted with competitors’ rapid release cycles. Internal organizational structure, with AI research split across multiple teams, slowed unified development.
Google responded with significant reorganization. The company merged Google Brain and DeepMind into a single entity, Google DeepMind, to consolidate AI research. PaLM 2 was released in May 2023, followed by the announcement of Gemini as a next-generation model. AI capabilities were rapidly integrated across Google’s product suite, from Search to Workspace applications.
Open Source Models Enter the Field (July 2023)
Meta’s release of Llama 2 in July 2023 marked a shift in the foundation model landscape. While competitors offered API access to their models for subscription fees, Meta released Llama 2 weights for free download and use, with models ranging from 7 billion to 70 billion parameters.
The 7B model could run on consumer laptops with sufficient RAM, making local deployment feasible for many applications. The 13B model balanced capability and efficiency, suitable for small-scale commercial deployment. The 70B model approached GPT-3.5’s performance on many benchmarks while remaining small enough for deployment on single GPUs.
The open-source release catalyzed rapid innovation. Within days, Stanford researchers released Alpaca, a fine-tuned version for instruction following. The Vicuna model claimed performance approaching ChatGPT on many tasks. Within months, hundreds of fine-tuned variants appeared on platforms like Hugging Face, as organizations adapted the base models for specific use cases.
Meta’s strategic decision reflected lessons from the mobile platform era. By open-sourcing Llama, Meta aimed to prevent dependence on competitors’ AI infrastructure while fostering an ecosystem around their models and PyTorch framework. This approach positioned Meta’s technology stack as essential infrastructure for the AI community, similar to Linux’s role in server computing.
Mistral AI and European Development (December 2023)
Mistral AI, founded by former DeepMind and Meta researchers, raised $113 million in seed funding and released their first model within six months. The company represented European efforts to develop competitive foundation models:
Mixtral 8x7B used sparse Mixture of Experts: - 47B total parameters, but only 13B active per token - Matched GPT-3.5 performance at 1/5 the compute - Ran on consumer GPUs that couldn’t handle dense 70B models - Apache 2.0 license - truly open, even for commercial use
The technical insight: not every token needs every parameter. Route tokens to specialized experts. It was an old idea (Hinton, 1991) that had become practical.
The Multimodal Revolution: Beyond Text (2024)
The boundaries between modalities are dissolving. Modern AI doesn’t just process text or images or audio separately - it’s starting to understand the relationships between them.
Voice: The Return of Natural Conversation
GPT-4o Voice Mode (May 2024)
OpenAI’s voice interface achieved 232 millisecond average response latency, comparable to human conversation at around 250ms. The system handled interruptions, expressed emotional nuance through prosody, and could switch between languages mid-sentence. It understood and generated non-verbal sounds like laughter and hesitations.
The technical approach used end-to-end speech-to-speech processing without intermediate text representation. The model operated directly on audio tokens, preserving intonation, emotion, and timing that text-based systems lost through transcription and synthesis stages.
Gemini Live (August 2024)
Google’s Gemini Live extended multimodal interaction to continuous screen understanding. The system could observe and comment on screen content during conversation, providing real-time assistance with coding, form completion, and other tasks. It maintained context across application switches, effectively serving as a persistent assistant aware of the user’s digital environment.
These systems raised privacy considerations as they required continuous audio and video streaming to cloud servers. Every conversation and screen interaction was potentially recorded and analyzed, creating a significant tradeoff between assistance capabilities and data privacy.
Video: The Final Frontier
Sora (February 2024)
OpenAI’s Sora showed that large-scale video training can create some implicit understanding of physics. The system generated 60-second coherent videos at up to 1920x1080 resolution and 24-60 fps - longer than previous systems limited to 4-second clips. It maintained object permanence when items moved off-screen and handled reflections and shadows reasonably well.
The model seemed to learn physical rules without explicit programming - glass shattering appropriately, liquids flowing with reasonable physics, shadows moving consistently with light sources. How much the model “understands” versus pattern-matches is still debated, but the results are notable.
Runway Gen-3 Alpha: Professional Video Generation (June 2024)
Runway focused on practical tools for filmmakers rather than technical demonstrations. Their Gen-3 Alpha provided motion brush controls allowing users to paint regions where movement should occur, precise camera controls for dolly, pan, and zoom movements, and maintained visual style consistency across multiple shots. The system output 4K production-ready video and offered API access for integration into professional post-production workflows.
The adoption in the film industry was rapid. Major studios began using the technology for previsualization, allowing directors to explore shots before expensive production. Independent filmmakers gained access to visual effects previously requiring large budgets. Advertising agencies could generate multiple creative variations instantly, and the overall cost of certain visual effects decreased by orders of magnitude.
Embodied AI: Physical Intelligence
Figure 01 and OpenAI Partnership (January 2024)
The collaboration between Figure and OpenAI brought large language models into robotic control. GPT-4V processed visual input from the robot’s cameras, enabling natural language task instructions and visual reasoning about the environment. Neural networks controlled actuators directly, eliminating traditional robotic programming layers. The system demonstrated rapid learning, acquiring new manipulation tasks within 10 hours of training.
A demonstration at BMW’s manufacturing facility in March 2024 showed practical applications. The Figure 01 robot performed sheet metal insertion with 0.1mm precision, adapted to variations in part positioning without reprogramming, and worked safely alongside human workers. It learned new assembly tasks through demonstration rather than explicit programming.
Tesla Optimus Gen 2 (December 2023)
Tesla’s second-generation humanoid robot improved substantially on key specifications. Each hand featured 11 degrees of freedom, enabling fine manipulation tasks. Walking speed increased to 8 km/h from the previous generation’s 3 km/h. The robot operated for 8 hours on a single charge, suitable for a work shift. Tesla targeted a $20,000 unit cost at scale, using the same neural network computer that powered their Full Self-Driving system in vehicles.
Real-world deployment in 2024 focused on structured industrial tasks. Tesla factories used Optimus robots for sorting battery cells, moving parts between workstations, and performing simple quality control inspections. These deployments still required human supervision, but demonstrated progress toward autonomous physical labor.
The progress in embodied AI addressed Moravec’s Paradox - the observation that high-level reasoning requires relatively little computation, but low-level sensorimotor skills require enormous computational resources. For decades, AI could master chess but not walking. Now, with sufficient compute and training data, even complex physical tasks were becoming tractable.
Advanced Capabilities: The New Primitives (2023-2024)
Visual Intelligence: Beyond Recognition
Segment Anything Model (SAM) - Meta, April 2023
Meta’s Segment Anything Model demonstrated general-purpose image segmentation without task-specific training. The model was trained on 1 billion masks across 11 million images, creating a foundation model for segmentation tasks. Users could specify objects through multiple modalities - clicking points, drawing boxes, or providing text descriptions. The system achieved zero-shot generalization to new domains including medical imaging, microscopy, and satellite imagery, while maintaining real-time performance at 50 milliseconds per image on consumer hardware.
SAM transformed segmentation from a specialized task requiring domain-specific labeled data into a general capability. Medical researchers applied it to tumor boundary detection, biologists used it for cell counting and tracking, and agricultural applications included crop health analysis. The model’s generality enabled diverse applications without retraining.
ControlNet: Precise Generation Control (February 2023)
ControlNet addressed a fundamental limitation of diffusion models: the inability to specify precise spatial and structural constraints. While users could prompt for “a cat,” they couldn’t control exact pose, composition, or spatial arrangement.
The solution involved conditioning image generation on various control signals. OpenPose skeletons enabled precise pose specification for human and animal figures. Canny edge maps preserved structural outlines while allowing style variation. MiDaS depth maps maintained three-dimensional consistency across generated images. Semantic segmentation maps specified different regions for targeted generation.
This precise control transformed creative workflows. Artists could maintain exact compositions while exploring stylistic variations. Animation studios achieved character consistency across frames. Architects could iterate on designs while preserving structural elements. The technology bridged the gap between creative freedom and precise control.
Code Generation: From Autocomplete to Autonomy
GitHub Copilot X: Comprehensive Development Assistant (March 2023)
GitHub Copilot evolved beyond line completion to comprehensive development assistance. The chat interface explained complex functions and generated documentation on demand. It automatically created pull request descriptions summarizing code changes, wrote test suites based on implementation, and fixed specific bugs when given descriptions. Voice control enabled coding through verbal logic description.
By 2024, Copilot’s impact was measurable: 40% of code in enabled projects was AI-assisted, with a 55% acceptance rate for suggestions. Developers reported 30% faster development velocity, leading to 1.5 million paid subscribers adopting the tool.
Devin: Autonomous Software Development (March 2024)
Cognition AI’s Devin moved beyond coding assistance to autonomous project completion. The system could handle complete software projects from requirements to deployment, identify and fix bugs in existing codebases, read documentation to learn new APIs and frameworks, write and run comprehensive test suites, and configure deployment infrastructure including servers, databases, and CI/CD pipelines.
On the SWE-bench benchmark, which measures ability to resolve real GitHub issues, Devin resolved 13.86% of issues autonomously, compared to GPT-4’s 1.74%. Human junior developers typically resolve 20-30% of such issues, placing Devin’s performance in a meaningful range for practical applications.
Devin’s workflow followed a structured approach: receiving tasks in natural language, planning approaches transparently, writing code iteratively with testing, fixing failures automatically, deploying and verifying results, and documenting all changes. This systematic process enabled autonomous handling of complex software engineering tasks.
Early deployments demonstrated practical capabilities through real client work: creating data visualization dashboards, implementing API integrations, building web scraping tools, performing database migrations, and fixing bugs in production codebases.
The implications for software development are unclear. Early evidence suggests augmentation rather than replacement - developers focusing on architecture, requirements, and review while AI handles more of the implementation.
The Competition Intensifies (2024)
By December 2024, the competitive landscape had crystallized around distinct performance tiers. The reasoning models - o3 at 95% and o1-preview at 92% - led in capability but required substantial compute. Claude 3.5 Sonnet at 88% balanced strong performance with practical deployment costs. DeepSeek V3’s achievement of matching Claude 3.5’s performance at one-tenth the cost demonstrated the potential for efficient architectures. Open models reached new heights with Llama 3.3 70B achieving 80% performance without API costs, while speed-optimized models like Gemini 2.0 Flash delivered 82% performance at $0.075 per million tokens.
The progression through 2024 showed accelerating capability improvements. Claude 3’s Q1 launch established new performance benchmarks across multiple domains. GPT-4o in Q2 introduced true omni-modal capabilities at reduced costs. The Q3 release of Llama 3.1 405B brought frontier-level performance to open-source models. Finally, Q4’s o1 and o3 models demonstrated genuine reasoning capabilities through test-time compute scaling.
Latest Developments (Late 2024)
The Reasoning Revolution: OpenAI o-series
December 20, 2024: OpenAI o3
The o-series represents a shift from pattern matching to something more like systematic reasoning. These models don’t just retrieve information - they work through problems step by step.
The o3 model’s performance on several benchmarks was notable. On ARC-AGI, it achieved 87.5%, becoming the first AI to exceed average human performance of 85% on abstract reasoning tasks. Its 88.7% score on GPQA Diamond demonstrated PhD-level understanding of science questions that challenge most specialists. In mathematics, o3 scored 96.7% on the AIME 2024, missing only one problem on this elite competition. Its Codeforces rating of 2,727 would place it 175th globally at Grandmaster level. On practical software engineering, it resolved 71.7% of issues in the SWE-Bench Verified dataset, demonstrating ability to fix real bugs in production repositories.
The key innovation was test-time compute scaling. Rather than using fixed compute for all queries, o3 dynamically allocated resources based on problem difficulty. Simple questions received quick responses with minimal compute. Complex problems triggered extended reasoning periods using orders of magnitude more compute. The model exposed its chain of thought, making errors interpretable and debuggable.
For the ARC-AGI benchmark, o3-high used roughly $3,700 of compute per task - but solved problems that appeared to require abstract reasoning rather than pattern matching. This trade-off between compute and capability is worth watching.
While OpenAI hasn’t disclosed the technical details, the architecture likely builds on a GPT-4-class base model enhanced with process supervision rather than just outcome supervision. The training appears to use reinforcement learning specifically on chain-of-thought reasoning, potentially incorporating techniques from AlphaZero and MuZero for planning. The system may implement Monte Carlo Tree Search or similar algorithms for exploring solution paths during inference.
DeepSeek V3: Efficiency Through Innovation (December 2024)
A team of 20 researchers in Hangzhou showed that strong AI capabilities don’t require Silicon Valley-scale resources.
DeepSeek V3’s economics were notable. Training cost just $5.57 million compared to GPT-4’s estimated $100 million. The model uses 671 billion total parameters with only 37 billion active per token through Mixture of Experts architecture. Performance reached 88.5% on MMLU, matching Claude 3.5 Sonnet. Training completed in 2 months using 2,000 H800 GPUs. The entire team consisted of 20 people, compared to OpenAI’s 375+ employees.
DeepSeek V3 introduced several technical innovations that enabled its efficiency.
Multi-Token Prediction (MTP) represents a fundamental shift in language modeling. Rather than predicting one next token, the model predicts eight tokens simultaneously. This forces the model to plan ahead, improving coherence and reasoning while reducing the sequential decoding bottleneck. The result is 3x faster inference with improved output quality.
The team solved the Mixture of Experts routing problem through auxiliary-loss-free load balancing. Each expert processes exactly the same number of tokens, preventing expert collapse or underutilization while ensuring perfectly balanced computation across the network.
FP8 mixed precision training stored weights in 8-bit floating point while computing in 16-bit for stability. This achieved 50% memory reduction and 40% speed improvement without quality degradation.
These innovations demonstrated several important principles. Efficient architecture can achieve frontier performance without excessive compute budgets. Open models have reached parity with closed commercial systems. Geographic constraints on hardware access can be overcome through algorithmic innovation. Small, focused teams can achieve breakthroughs that rival large organizations.
The open-source release of code and weights, combined with the ability to run on relatively modest hardware, lowers barriers to advanced AI deployment.
Andrej Karpathy’s introduction to LLMs - useful for understanding modern AI
Some Closing Thoughts
A few patterns came up repeatedly in this history:
The simplest solutions kept winning. Backpropagation is just the chain rule. Attention is weighted averaging. ReLU is max(0,x). The ideas that changed everything were often embarrassingly simple in hindsight.
Scale beat cleverness. Every time we tried to encode human knowledge directly - expert systems, hand-crafted features, symbolic reasoning - learning from data at scale won. Rich Sutton called this the “bitter lesson.”
We built before we understood. We could fly before we understood aerodynamics. We’re building capable AI systems before we fully understand intelligence. That’s how a lot of progress actually happens.
Progress came in jumps. The Perceptron’s death, AlexNet’s breakthrough, ChatGPT’s launch - the field advanced through discontinuous leaps rather than gradual improvement.
After going through this history, what strikes me most is that we still don’t really understand why these systems work as well as they do. We can build them, train them, and deploy them, but the internal mechanisms remain largely opaque. A model with hundreds of billions of parameters can’t be easily simplified or explained.
I’ve certainly missed important developments and probably mischaracterized some things. The field moves fast, and parts of this are likely already outdated. But I hope it’s useful as an overview of how we got here.
The resources section below has papers and courses that go much deeper. The field is more accessible than ever - most important papers are freely available, and capable models can run on consumer hardware.
Thanks for reading.
Essential Resources
Essential Papers in AI History
Foundational Works (1943-1969)
- McCulloch & Pitts (1943) - A Logical Calculus of Ideas Immanent in Nervous Activity
- Turing (1950) - Computing Machinery and Intelligence
- Rosenblatt (1958) - The Perceptron: A Probabilistic Model
- Minsky & Papert (1969) - Perceptrons
- Samuel (1959) - Some Studies in Machine Learning Using the Game of Checkers
- Widrow & Hoff (1960) - Adaptive Switching Circuits (ADALINE)
The Learning Revolution (1974-1998)
- Werbos (1974) - Beyond Regression: New Tools for Prediction (Backpropagation thesis)
- Rumelhart, Hinton & Williams (1986) - Learning representations by back-propagating errors
- Hinton & Salakhutdinov (2006) - Reducing dimensionality with neural networks
- Hochreiter & Schmidhuber (1997) - Long Short-Term Memory
- LeCun et al. (1989) - Backpropagation Applied to Handwritten Zip Code Recognition
- LeCun et al. (1998) - Gradient-based learning applied to document recognition
- Bellman (1957) - Dynamic Programming
Statistical Learning (1995-2011)
- Cortes & Vapnik (1995) - Support Vector Networks
- Breiman (2001) - Random Forests
- Freund & Schapire (1997) - A Decision-Theoretic Generalization of On-Line Learning (AdaBoost)
- Friedman (2001) - Greedy Function Approximation: A Gradient Boosting Machine
- Tibshirani (1996) - Regression Shrinkage and Selection via the Lasso
- Blei, Ng & Jordan (2003) - Latent Dirichlet Allocation
Deep Learning Era (2012-2016)
- Krizhevsky et al. (2012) - ImageNet Classification with Deep CNNs (AlexNet)
- Szegedy et al. (2015) - Going Deeper with Convolutions (GoogLeNet)
- He et al. (2015) - Deep Residual Learning for Image Recognition (ResNet)
- Ioffe & Szegedy (2015) - Batch Normalization
- Srivastava et al. (2014) - Dropout: A Simple Way to Prevent Neural Networks from Overfitting
- Goodfellow et al. (2014) - Generative Adversarial Networks
- Kingma & Ba (2014) - Adam: A Method for Stochastic Optimization
- Simonyan & Zisserman (2014) - Very Deep Convolutional Networks (VGGNet)
- Huang et al. (2017) - Densely Connected Convolutional Networks
- Kingma & Welling (2013) - Auto-Encoding Variational Bayes
Attention & Transformers (2014-2020)
- Bahdanau et al. (2014) - Neural Machine Translation by Jointly Learning to Align and Translate
- Luong et al. (2015) - Effective Approaches to Attention-based Neural Machine Translation
- Vaswani et al. (2017) - Attention Is All You Need
- Peters et al. (2018) - Deep Contextualized Word Representations (ELMo)
- Radford et al. (2018) - Improving Language Understanding by Generative Pre-Training (GPT-1)
- Devlin et al. (2018) - BERT: Pre-training of Deep Bidirectional Transformers
- Liu et al. (2019) - RoBERTa: A Robustly Optimized BERT Pretraining Approach
- Raffel et al. (2019) - T5: Text-to-Text Transfer Transformer
- Brown et al. (2020) - Language Models are Few-Shot Learners (GPT-3)
- Kaplan et al. (2020) - Scaling Laws for Neural Language Models
- Hoffmann et al. (2022) - Training Compute-Optimal Large Language Models (Chinchilla)
Multimodal & Vision (2020-2022)
- Chen et al. (2020) - SimCLR: Contrastive Learning of Visual Representations
- He et al. (2020) - Momentum Contrast (MoCo)
- Grill et al. (2020) - Bootstrap Your Own Latent (BYOL)
- Chen & He (2021) - Exploring Simple Siamese Representation Learning
- Dosovitskiy et al. (2021) - An Image is Worth 16x16 Words (ViT)
- Radford et al. (2021) - Learning Transferable Visual Models From Natural Language Supervision (CLIP)
- Ramesh et al. (2021) - Zero-Shot Text-to-Image Generation (DALL-E)
- He et al. (2022) - Masked Autoencoders Are Scalable Vision Learners (MAE)
- Alayrac et al. (2022) - Flamingo: a Visual Language Model for Few-Shot Learning
Diffusion Models & Generation (2020-2023)
- Ho et al. (2020) - Denoising Diffusion Probabilistic Models
- Song et al. (2021) - Score-Based Generative Modeling through SDEs
- Dhariwal & Nichol (2021) - Diffusion Models Beat GANs on Image Synthesis
- Nichol et al. (2022) - GLIDE: Towards Photorealistic Image Generation
- Rombach et al. (2022) - High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion)
- Saharia et al. (2022) - Photorealistic Text-to-Image Diffusion Models (Imagen)
- Singer et al. (2023) - Make-A-Video: Text-to-Video Generation without Text-Video Data
- Poole et al. (2023) - DreamFusion: Text-to-3D using 2D Diffusion
Large Language Models & RLHF (2022-2024)
- Ouyang et al. (2022) - Training language models to follow instructions with human feedback (InstructGPT)
- Anthropic (2022) - Constitutional AI: Harmlessness from AI Feedback
- Touvron et al. (2023) - LLaMA: Open and Efficient Foundation Language Models
- OpenAI (2023) - GPT-4 Technical Report
- Anthropic (2023) - Claude 2 Technical Report
- Jiang et al. (2023) - Mistral 7B
- Jiang et al. (2024) - Mixtral of Experts
- Gemini Team (2023) - Gemini: A Family of Highly Capable Multimodal Models
- DeepSeek (2024) - DeepSeek-V3 Technical Report
- OpenAI (2024) - Learning to Reason with LLMs (o1)
Where to Learn More
Visual & Interactive Learning
- 3Blue1Brown Neural Network Series: Grant Sanderson’s brilliant visual explanations
- The Illustrated Transformer: Jay Alammar’s visual guide to transformers
- Distill.pub: Interactive visualizations of ML concepts
- Lil’Log: Lilian Weng’s comprehensive ML tutorials
- The Annotated Transformer: Line-by-line implementation in PyTorch
- CNN Explainer: Interactive CNN visualization
- Transformer Explainer: Interactive transformer visualization
- Seeing Theory: Visual introduction to probability and statistics
- TensorFlow Playground: Interactive neural network in your browser
- Understanding LSTM Networks: Chris Olah’s classic LSTM explanation
- The Neural Network Zoo: Visual guide to neural architectures
University Courses (Free)
- Stanford CS231n: Convolutional Neural Networks for Visual Recognition (Fei-Fei Li, Andrej Karpathy)
- Stanford CS224n: Natural Language Processing with Deep Learning (Chris Manning)
- MIT 6.034: Artificial Intelligence (Patrick Winston)
- MIT 6.S191: Introduction to Deep Learning
- Berkeley CS182: Deep Learning
- Berkeley CS285: Deep Reinforcement Learning (Sergey Levine)
- CMU 11-785: Introduction to Deep Learning
- NYU Deep Learning: Yann LeCun and Alfredo Canziani
- Fast.ai Practical Deep Learning: Top-down practical approach (Jeremy Howard)
- DeepLearning.AI Specializations: Andrew Ng’s comprehensive courses
- Full Stack Deep Learning: Production ML engineering
- Harvard CS50 AI: Introduction to AI with Python
Books & Textbooks
- Deep Learning by Goodfellow, Bengio, Courville: The definitive textbook (free online)
- Pattern Recognition and Machine Learning by Bishop: Bayesian perspective (free PDF)
- The Elements of Statistical Learning by Hastie, Tibshirani, Friedman: Statistical foundations (free PDF)
- Dive into Deep Learning: Interactive book with code
- Understanding Deep Learning by Simon Prince: Modern comprehensive text (2023, free)
- Probabilistic Machine Learning by Kevin Murphy: Two-volume modern treatment
- Speech and Language Processing by Jurafsky & Martin: NLP bible (free)
- Reinforcement Learning: An Introduction by Sutton & Barto: RL classic (free)
- Mathematics for Machine Learning by Deisenroth et al.: Mathematical foundations (free)
- The Little Book of Deep Learning by François Fleuret: Concise introduction (free)
- Neural Networks and Deep Learning by Michael Nielsen: Intuitive introduction (free)
Key Figures to Follow
- Geoffrey Hinton: Godfather of deep learning
- Yann LeCun: Meta Chief AI Scientist
- Yoshua Bengio: Scientific Director of Mila
- Demis Hassabis: DeepMind CEO
- Ilya Sutskever: OpenAI Chief Scientist
- Fei-Fei Li: Stanford AI Lab Director
- Andrew Ng: DeepLearning.AI founder
- Andrej Karpathy: Former Tesla AI Director
- Chris Olah: Anthropic researcher, visualization expert
- François Chollet: Keras creator, ARC challenge
- Ian Goodfellow: GANs inventor
- Oriol Vinyals: DeepMind Principal Scientist
- Dario Amodei: Anthropic CEO
- Sam Altman: OpenAI CEO
- Faisal Mahmood: Harvard Medical School, Computational Pathology Pioneer
Copyright & Citation
© 2026 Rowland W. Pettit. All rights reserved.
Citation: Pettit, R.W. (2026). “AI: A Technical History.” Available at: rowlandpettit.github.io/machine-learning.html
:::